键树的基本概念
键树又称数字查找树(Digital Search Tree)。
它是一棵度大于等于2的树,树中的每个结点中不是包含一个或几个关键字,而是只含有组成关键字的符号。
例如,若关键字是数值,则结点中只包含一个数位;若关键字是单词,则结点中只包含一个字母字符。
这种树会给某种类型关键字的表的查找带来方便。
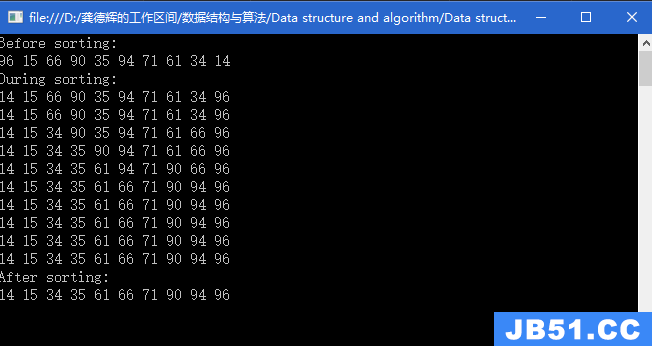
如下图所示为一棵键树:
从根到叶子结点路径中结点的字符组成的字符串表示一个关键字,叶子结点中的特殊符号$表示字符串的结束。
在叶子结点中还含有指向该关键字记录的指针。
为了查找和插入方便,我们约定键树是有序树,即同一层中兄弟结点之间依所含符号自左至右有序,并约定$小于任何字符。
键树中每个结点的最大度d和关键字的“基”有关,若关键字是单词,则d=27,若关键字是数值,则d=11。
键树的深度h则取决于关键字中字符或数位的个数。
通常,键树可有两种存储结构,分别称为双链树和Trie树。
双链树
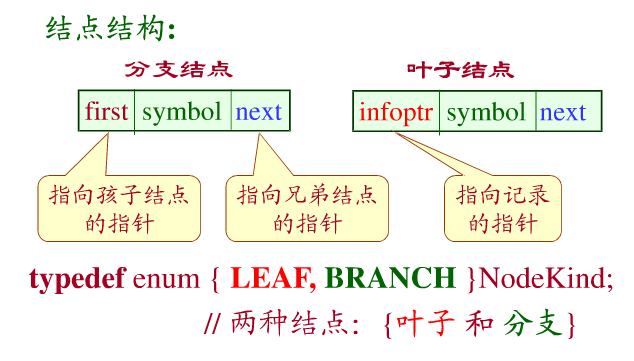
以树的孩子兄弟链表来表示键树,则每个分支结点包括三个域:
symbol域:存储关键字的一个字符;
first域:存储指向第一棵子树根的指针;
next域:存储指向右兄弟的指针。
同时,叶子结点不含first域,它的infoptr域存储指向该关键字记录的指针。
此时的键树又称双链树。
在双链树中插入或删除一个关键字,相当于在树中某个结点上插入或删除一棵子树。
结点的结构中可以设置一个枚举变量表示结点的类型,叶子结点和分支结点。
叶子结点和分支结点都有symbol域和next域。不同的一个域可以用联合表示,叶子结点包含infoptr指向记录,而分支结点是first域指向其第一棵子树。

双链树如下图:
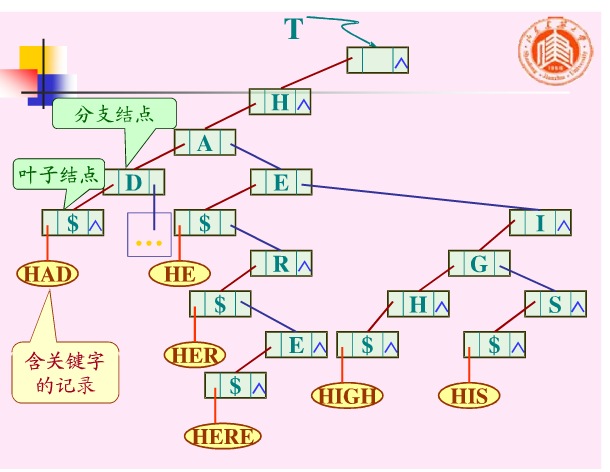
双链树的查找可如下进行:
假设给定值为K.ch(0..num-1),其中K.ch[0]至 K.ch[num-2]表示待查关键字中num-1个字符, K.ch[num-1]为结束符$。
从双链树的根指针出发,顺first指针找到第一棵子树的根结点,以K.ch[0]和此结点的symbol域比较,若相等,则顺first域再比较下一字符,否则沿next域顺序查找。
若直至空仍比较不等,则查找不成功。
下面是算法表示的代码:

双链树查找

#define MAXKEYLEN 16 typedef struct { char ch[MAXKEYLEN]; //keyword int num; }KeysType; typedef enum { LEAF,BRANCH }NodeKind; typedef DLTNode { char symbol; struct DLTNode *next; NodeKind kind; union { Record *infoptr; first; }; }DLTNode,*DLTree; Record *SearchDLTree(DLTree T,KeysType K) { DLTNode p=T->first; int i=0; while(p && i<K.num) { while(p && p->symbol!= K.ch[i]) { p=p->next; } if(p && i<K.num-1) { p=p->first; } ++i; }search end if(!p) { return NULL; search fail } else { return p->infoptr; find } }
Trie树
若以树的多重链表表示键树,则树的每个结点中应含有d个指针域,此时的键树又称Trie树。
(Trie是从检索retrieve中取中间四个字符的,读音同try)。
若从键树中某个结点到叶子结点的路径上每个结点都只有一个孩子,则可将该路径上所有结点压缩成一个“叶子结点”,且在该叶子结点中存储关键字及指向记录的指针等信息。
在Trie树中有两种结点:
分支结点:含有d个指针域和一个指示该结点中非空指针域的个数的整数域。在分支结点中不设数据域,每个分支结点所表示的字符均有其父结点中指向该结点的指针所在位置决定。
叶子结点:含有关键字域和指向记录的指针域。


Trie树如下图:
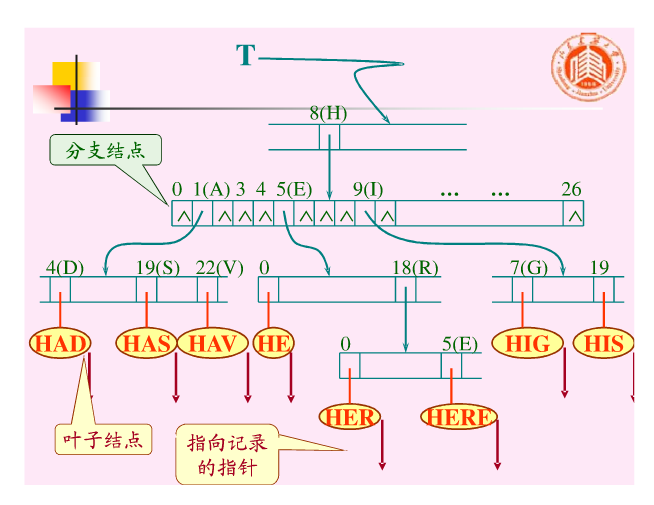
在Trie树上进行查找的过程为:
从根结点出发,沿和给定值相应的指针逐层向下,直至叶子结点,若叶子结点中的关键字和给定值相等,则查找成功,若分支结点中和给定值相应的指针为空,或叶子结点中的关键字和给定值不相等,则查找不成功。
算法表示如下:
Trie树查找
typedef TrieNode { NodeKind kind; union { struct {KeysType K; Record *infoptr;}lf; Leaf Node struct {TrieNode *ptr[27]; int num;}bh; Branch Node }; }TrieNode,1)">TrieTree; Record *SearchTrie(TrieTree T,KeysType K) { TrieNode p; for(p=T,i=0; p && p->kind == BRANCH && i<K.num; p=p->bh.ptr[ord(K.ch[i]),++i]) ; if(p && p->kind==LEAF && p->lf.K==K) { return p->lf.infoptr; } return NULL; } }
其中ord方法将字符转换成该字符在字母表中的序号,并假设$的序号为零。
(这个for循环写得真DT。)
本文资料来源:严蔚敏《数据结构》,文中图片来源于百度文库的PPT,代码是算法表示的伪代码,还不能直接运行。
关于Trie树,这里有篇博文:http://www.cnblogs.com/dolphin0520/archive/2011/10/11/2207886.html
本文转载自:https://www.cnblogs.com/mengdd/archive/2012/11/15/2772418.html