原文链接:http://blog.csdn.net/qq_38646470/article/details/79431659
1.概念:
如果想判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。链表,树等等数据结构都是这种思路. 但是随着集合中元素的增加,我们需要的存储空间越来越大,检索速度也越来越慢。不过世界上还有一种叫作散列表(又叫哈希表,Hash table)的数据结构。它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit Array)中的一个点。这样一来,我们只要看看这个点是不是 1 就知道可以集合中有没有它了。这就是布隆过滤器的基本思想。
它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率(假正例False positives,即Bloom Filter报告某一元素存在于某集合中,但是实际上该元素并不在集合中)和删除困难,但是没有识别错误的情形(即假反例False negatives,如果某个元素确实没有在该集合中,那么Bloom Filter 是不会报告该元素存在于集合中的,所以不会漏报)。
2.实现原理:
直观的说,bloom算法类似一个hash set,用来判断某个元素(key)是否在某个集合中。和一般的hash set不同的是,这个算法无需存储key的值,对于每个key,只需要k个比特位,每个存储一个标志,用来判断key是否在集合中。
算法:
1). 首先需要k个hash函数,每个函数可以把key散列成为1个整数
2). 初始化时,需要一个长度为range比特的数组,每个比特位初始化为0
3). 某个key加入集合时,用k个hash函数计算出k个散列值,并把数组中对应的比特位置为1
4). 判断某个key是否在集合时,用k个hash函数计算出k个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,认为在集合中。
3.代码实现:
采用3个hash函数计算散列值。
布隆结构设计:
typedef char* KeyType;
typedef size_t(*HASH_FUNC)(KeyType str);
typedef struct BloomFilter
{
BitMap _bm;
HASH_FUNC _Hashfunc1;
HASH_FUNC _Hashfunc2;
HASH_FUNC _Hashfunc3;
}BloomFilter;
hash函数:
static size_t BKDRHash(KeyType str)
{
unsigned int seed = 131; // 31 131 1313 13131 131313
unsigned int hash = 0;
while (*str )
{
hash = hash * seed + (*str++);
}
return (hash & 0x7FFFFFFF);
}
size_t DEKHash(KeyType str)
{
if(!*str) // 这是由本人添加,以保证空字符串返回哈希值0
return 0;
register size_t hash = 1315423911;
while (size_t ch = (size_t)*str++)
{
hash = ((hash << 5) ^ (hash >> 27)) ^ ch;
}
return hash;
}
size_t FNVHash(KeyType str)
{
if(!*str) // 这是由本人添加,以保证空字符串返回哈希值0
return 0;
register size_t hash = 2166136261;
while (size_t ch = (size_t)*str++)
{
hash *= 16777619;
hash ^= ch;
}
return hash;
}
bloom算法实现函数:
void BloomFilterInit(BloomFilter *bf,size_t range) //初始化
{
BitMapInit(&bf->_bm,range);
bf->_Hashfunc1 = BKDRHash;
bf->_Hashfunc2 = FNVHash;
bf->_Hashfunc3 = DEKHash;
}
void BloomFilterSet(BloomFilter *bf,KeyType key)//标记相应位
{
assert(bf);
BitMapSet(&bf->_bm,bf->_Hashfunc1(key)%bf->_bm._range);
BitMapSet(&bf->_bm,bf->_Hashfunc2(key)%bf->_bm._range);
BitMapSet(&bf->_bm,bf->_Hashfunc3(key)%bf->_bm._range);
}
int BloomFilterTest(BloomFilter *bf,KeyType key)
{
assert(bf);
if (BitMapTest(&bf->_bm,bf->_Hashfunc1(key)%bf->_bm._range))
return -1;
if (BitMapTest(&bf->_bm,bf->_Hashfunc2(key)%bf->_bm._range))
return -1;
if (BitMapTest(&bf->_bm,bf->_Hashfunc3(key)%bf->_bm._range))
return -1;
return 0;
}
void BloomFilterDestory(BloomFilter *bf) //销毁
{
BitMapDestory(&bf->_bm);
}
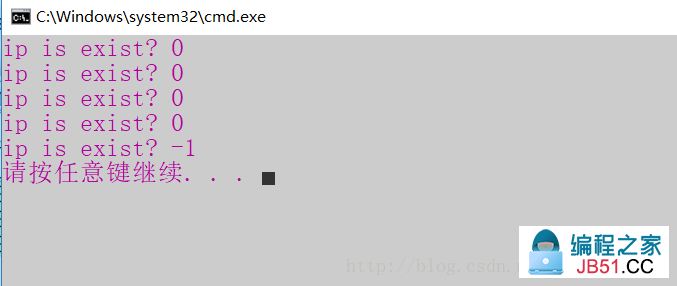
算法测试案例及运行结果:
void TestBlooomFilter()
{
BloomFilter bf;
BloomFilterInit(&bf,-1);
BloomFilterSet(&bf,"123.5.3.6");
BloomFilterSet(&bf,"123.5.3.8");
BloomFilterSet(&bf,"123.5.3.7");
BloomFilterSet(&bf,"123.5.3.4");
BloomFilterSet(&bf,"123.5.3.6");
printf("ip is exist? %d\n",BloomFilterTest(&bf,"123.5.3.6"));
printf("ip is exist? %d\n","123.5.3.7"));
printf("ip is exist? %d\n","123.5.3.8"));
printf("ip is exist? %d\n","123.5.3.4"));
printf("ip is exist? %d\n","123.5.3.1"));
BloomFilterDestory(&bf);
}
0 代表存在 ,-1代表不存在。
代码中调用了位图相关函数代码: 位图相关部分知识在上篇博文中有详细解释。
#define _CRT_SECURE_NO_WARNINGS 1
#include"BitMap.h"
void BitMapInit(BitMap *bm,size_t range) //初始化
{
assert(bm);
bm->_bits = NULL;
bm->_range = range;
bm->_bits = (size_t *)malloc(sizeof(char)*bm->_range/8 +1);
assert(bm->_bits);
memset(bm->_bits,sizeof(char)*bm->_range/8 +1);
}
void BitMapSet(BitMap *bm,size_t x)//标记相应位
{
size_t num = x>>5;
size_t bit = x%32;
bm->_bits[num] |=(1<<bit);
}
int BitMapTest(BitMap *bm,size_t x)
{
size_t num = x>>5;
size_t bit = x%32;
if ((1<<bit)&bm->_bits[num])
return 0;
return -1;
}
void BitMapDestory(BitMap *bm)
{
free(bm->_bits);
bm->_bits = NULL;
bm->_range = 0;
}
4.布隆过滤器的实际用例[1]
Google 著名的分布式数据库 Bigtable 使用了布隆过滤器来查找不存在的行或列,以减少磁盘查找的IO次数。
Squid 网页代理缓存服务器在 cache digests 中使用了也布隆过滤器。
Venti 文档存储系统也采用布隆过滤器来检测先前存储的数据。
SPIN 模型检测器也使用布隆过滤器在大规模验证问题时跟踪可达状态空间。
Google Chrome浏览器使用了布隆过滤器加速安全浏览服务。
在很多Key-Value系统中也使用了布隆过滤器来加快查询过程,如 Hbase,Accumulo,eveldb,一般而言,Value 保存在磁盘中,访问磁盘需要花费大量时间,然而使用布隆过滤器可以快速判断某个Key对应的Value是否存在,因此可以避免很多不必要的磁盘IO操作,只是引入布隆过滤器会带来一定的内存消耗,下图是在Key-Value系统中布隆过滤器的典型使用:
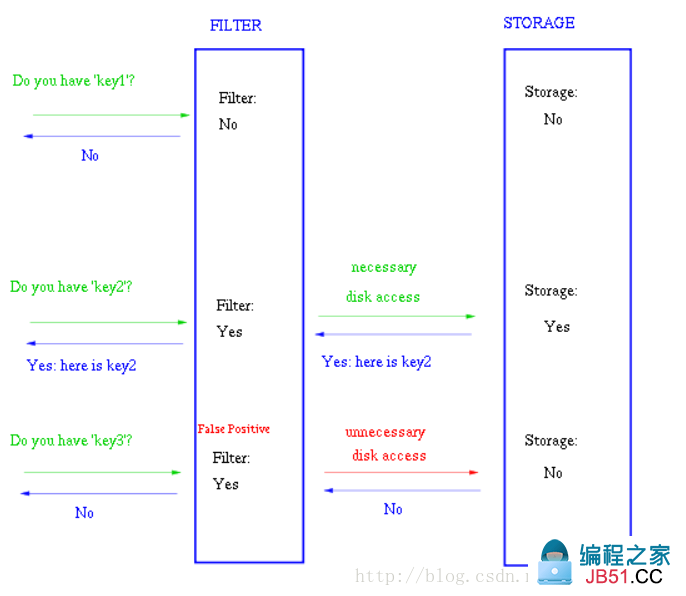
5.布隆过滤器相关扩展[1]
Counting filters
基本的布隆过滤器不支持删除(Deletion)操作,但是 Counting filters 提供了一种可以不用重新构建布隆过滤器但却支持元素删除操作的方法。在Counting filters中原来的位数组中的每一位由 bit 扩展为 n-bit 计数器,实际上,基本的布隆过滤器可以看作是只有一位的计数器的Counting filters。原来的插入操作也被扩展为把 n-bit 的位计数器加1,查找操作即检查位数组非零即可,而删除操作定义为把位数组的相应位减1,但是该方法也有位的算术溢出问题,即某一位在多次删除操作后可能变成负值,所以位数组大小 m 需要充分大。另外一个问题是Counting filters不具备伸缩性,由于Counting filters不能扩展,所以需要保存的最大的元素个数需要提前知道。否则一旦插入的元素个数超过了位数组的容量,false positive的发生概率将会急剧增加。当然也有人提出了一种基于 D-left Hash 方法实现支持删除操作的布隆过滤器,同时空间效率也比Counting filters高。
Data synchronization
Byers等人提出了使用布隆过滤器近似数据同步。
Bloomier filters
Chazelle 等人提出了一个通用的布隆过滤器,该布隆过滤器可以将某一值与每个已经插入的元素关联起来,并实现了一个关联数组Map。与普通的布隆过滤器一样,Chazelle实现的布隆过滤器也可以达到较低的空间消耗,但同时也会产生false positive,不过,在Bloomier filter中,某 key 如果不在 map 中,false positive在会返回时会被定义出的。该Map 结构不会返回与 key 相关的在 map 中的错误的值。
参考资料
[1] https://www.cnblogs.com/liyulong1982/p/6013002.html