分析算法最混乱的方面大概集中在对数上面。我们已经看到,某些分治算法将以O(N log N)时间运行。此外,对数最常出现的规律可概括为下列一般法则:
如果一个算法用常数时间(O(1))将问题的大小削减为其一部分(通常是1/2),那么该算法就是O(logN)。另一方面,如果使用常数时间只是把问题减少一个常数的数量(如将问题减少1),那么这种算法就是O(N)的。
下面,提供了具有对数特点的三个例子,分别为如下:
1.折半查找;
2.欧几里得算法;
3.幂运算;
一、折半查找
第一个例子通常叫做折半查找。
折半查找:给定一个整数X和整数A0,A1,.....,AN-1,后者已经预先排序并在内存中,求下标i使得Ai =X,如果X不在数据中,则返回i=-1。
明显的解法是从左到右扫描数据,其运行花费线性时间。然而,这个算法没有用到该表已经排序的事实,这就使得算法很可能不是最好的。一个好的策略是验证X是否是居中的元素。
如果是,则答案就找到了。如果X小于居中元素,那么我们可以应用同样的策略于居中元素左边已排序的子序列;同理,如果X大于居中元素,那么我们检查数据的右半部分。(同样,也存在可能会终止的情况)。
示例一(反映了Java语言数据下标从0开始的惯例):
public static <AnyType extends Comparable<? super AnyType>> int binarySearch(AnyType[] a,AnyType x) { int low = 0,high = a.length-1; while(low <=high) { int mid = (low+high)/2; if(a[mid].compareTo(x) < 0) low = mid + 1else if (a[mid].compareTo(x) > 0) high = mid - 1else return mid; } return -1;//NOT_FOUND }
显然,每次迭代在循环内的所有工作花费O(1),因此分析需要确定循环的次数。循环从high-low=N-1开始,并保持high-low >= -1。
每次循环后high-low的值至少将该次循环前的值折半;于是,循环的次数最多为[log(N-1)]+2。(例如,若high-low=128,则在各次迭代后high-low的最大值是64,32,16,8,4,2,1,0,-1。)因此,运行时间是O(logN)。与此等价,我们也可以写出运行时间的递推公式,不过,当我们理解实际在做什么以及为什么的原理时,这种强行写公式的做法通常没有必要。
折半查找可以看作是我们的第一个数据结构实现方法,它提供了在O(logN)时间内的contains操作,但是所有其他操作(特别是insert操作)均需要O(N)时间。在数据是稳定(即不允许插入操作和删除操作)的应用中,这种操作可能是非常有用的。此时输入数据需要一次排序,但是此后的访问会很快。有个例子是一个程序,它需要保留(产生于化学和物理领域的)元素周期表的信息。这个表是相对稳定的,因为很少会加进新的元素。元素名可以始终是排序的。由于只有大约110种元素,因此找出一个元素最多需要访问8次。要是执行顺序查找就会需要多得多的访问次数。
二、欧几里得算法
第二个例子是计算最大公因数的欧几里得算法。两个整数的最大公因数(gcd)是同时整除二者的最大整数。于是,gcd(50,15)=5。
示例二(所示的算法计算gcd(M,N),假设M>=N(如果N>M,则循环的第一次迭代将它们互相交换):
static long gcd(long m,long n) { while( n != 0) { long rem = m % n; m = n; n = rem; } m; }
算法连续计算余数直到余数是0为止,最后的非零余数就是最大公因数。因此,如果M=1989和N=1590,则余数序列是399,393,6,3,0。从而,gcd(1989,1590)=3。正如例子所表明的,这是一个快速算法。
如前所述,估计算法的整个运行时间依赖于确定余数序列究竟有多长。虽然logN看似像理想中的答案,但是根本看不出余数的值按照常数因子递减的必然性,因为我们看到,例中的余数从399仅仅降到393事实上,在一次迭代中余数并不按照一个常数因子递减。然而,我们可以证明,在两次迭代以后,余数最多是原始值的一半。这就证明了,迭代次数至多2 log N = O(logN)从而得到运行时间。这个证明并不难,因此我们将它放在这里,可从下列定理直接推出它。
定理2.1
如果M>N,则M mod N < M/2。
证明:
存在两种情形。如果N<=M/2,则由于余数小于N,故定理在这种情形下成立。另一种情形是N>M/2。但是此时M仅含有一个N从而余数为M-N < M/2,定理得证。
从上面的例子来看,2 log N 大约为20,而我们仅进行了7次运算,因此有人会怀疑这是不是可能的最好的界。事实上,这个常数在最坏的情况下还可以稍微改进1.44 log N(如M和N是两个相邻的斐波那契数时就是这种情况)。欧几里得算法在平均情况下的性能需要大量篇幅的高度复杂的数学分析,其迭代的平均次数约为(12 ln 2 lnN)/π2 + 1.47。
三、幂运算
最后一个例子是处理一个整数的幂(它还是一个整数)。由取幂运算得到的数一般都是相当大的,因此,我们只能在假设有一台机器能够存储这样一些大整数(或有一个编译程序能够模拟它)的情况下进行我们的分析。我们将用乘法的次数作为运行时间的度量。
计算XN 的明显的算法是使用N-1次乘法自乘。有一种递归算法效果较好。N<=1是这种递归的基准情形。否则,若N是偶数,我们有XN = XN/2 . XN/2 ,如果N是奇数,则XN = X(N-1)/2 .
X(N-1)/2 .X。
例如,为了计算X62,算法将如下进行,它只用到9次乘法:
X3 = (X3)X ,X7 = (X3)2X,X15 = (X7)2X,X31 = (X15)2X,X62 = (X31)2
显然,所需要的乘法次数最多是2logN,因为把问题分半最多需要两次乘法(如果N是奇数)。
这里,我们又可以写出一个递推公式并将其解出。简单的直觉避免了盲目的强行处理。
示例三:
long pow(long x,1)"> n) { if( n == 0) return 1; if( n == 1 x; if( isEven(n)) return pow(x * x,n/2); else x; } boolean isEven(return (n % 2 == 0); }
关于分析结果的准确性:
根据经验,有时分析会估计过大。如果这种情况发生,那么或者需要进一步细化分析(一般通过机敏的观察),或者可能是平均运行时间显著小于最坏情形的运行时间,不可能对所得的界再加以改进。对于许多复杂的算法,最坏的界通过某个坏的输入是可以达到的,但在实践中情形下仍然悬而未决),而最坏情形的界尽管过分地悲观,但却是最好的已知解析结果。
示例源码地址为:https://github.com/youcong1996/The-Data-structures-and-algorithms/tree/master/algorithm_analysis
 匿名组 这里可能用到几个不同的分组构造。通过括号内围绕的正...
匿名组 这里可能用到几个不同的分组构造。通过括号内围绕的正...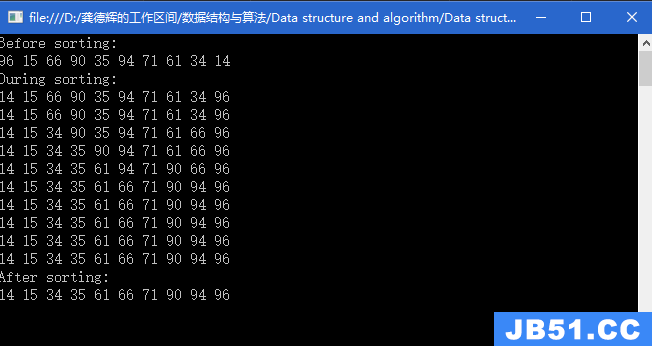 选择排序:从数组的起始位置处开始,把第一个元素与数组中其...
选择排序:从数组的起始位置处开始,把第一个元素与数组中其...