● 计数排序
1、算法思想:
计数排序是直接定址法的变形。通过开辟一定大小的空间,统计相同数据出现的次数,然后回写到原序列中。
2、步骤:
1)找到序列中的最大和最小数据,确定开辟的空间大小。
2)开辟空间,利用开辟的空间存放各数据的个数。
3)将排好序的序列回写到原序列中。
具体实现如下:
void CountSort(int *arr, int size)
{
assert(arr);
int min = arr[0];
int max = arr[0];
int num = 0;
for (int i = 0; i < size; ++i)//找出最大和最小数
{
if (arr[i] < min)
{
min = arr[i];
}
if (arr[i] > max)
{
max = arr[i];
}
}
num = max - min + 1;//开辟的空间大小
int *count = new int[num];
memset(count, 0, sizeof(int)*num);//初始化count
for (int i = 0; i < size; ++i)
{
count[arr[i] - min]++;//直接定址
}
int index = 0;
for (int i = 0; i < num; ++i)
{
while (count[i]--)
{
arr[index] = i + min;//回写到原序列中
index++;
}
}
}
优缺点:
优势:在对一定范围内的整数排序时,它的复杂度为Ο(n+k)(其中k是整数的范围),快于任何比较排序算法
劣势:基数排序需要开辟对应大小的空间,k较大时空间利用率不高,故适应于数据比较密集的序列。如果数据密集且没有重复,我们可以用位图实现。
● 基数排序
基数排序是典型的分配类排序,分配类排序是指利用分配和收集两种基本操作实现排序。基数排序通过反复的进行分配与收集操作完成排序,基数排序有两种排序方法,分别是“低位优先”和“高位优先”。在这里我以“低位优先”排序法进行分析。
排序时先按最低位的值对记录进行初步排序,在此基础上再按次低位的值进行进一步排序。以此类推,由低位到高位,每一趟都是在前一趟的基础上,根据关键字key的某一位对所有记录进行排序,直到最高位,这样就完成了基数排序的全过程。
2、步骤:
1)由于一直到最高位结束,故需找到最大数的位数。
2)开辟空间存放一趟排序后的序列。利用矩阵的快速转置思想,用count数组存放进行排序的位相同数字的个数,用start数组记录每次开始的位置,对每一个元素进行快速定位。
3)回写到原序列中。
4)重复以上步骤,直到比较到最高位为止。
具体实现如下:
void RadixSort(int *arr, int size)
{
assert(arr);
int *count = new int[10];//每位的数字在0~9之间
int *start = new int[10];
int *tmp = new int[size];//存放每趟排序后的序列
int MaxRadix = GetMaxRadix(arr, size);//最大数的位数
int radix = 1;
for (int k = 1; k <= MaxRadix; ++k)
{
memset(count, sizeof(int)* 10);//初始化count
memset(start, sizeof(int)* 10);
for (int i = 0; i < size; ++i)//count存放进行排序的位数相同的个数
{
count[(arr[i] / radix) % 10]++;
}
start[0] = 0;
for (int i = 1; i < 10; ++i)//start存放数据开始位置
{
start[i] = start[i - 1] + count[i - 1];
}
for (int i = 0; i < size; ++i)//快速定位
{
int num = (arr[i] / radix) % 10;
tmp[start[num]++] = arr[i];
}
memcpy(arr, tmp, sizeof(int)*size);//回写
radix *= 10;
}
delete[] tmp;//注意释放tmp
}
● 稳定性分析
稳定性指排序后在原序列中相同数据的相对位置不会发生改变。插入排序、冒泡排序、归并排序、计数排序和基数排序是稳定的;快速排序、希尔排序、堆排序和选择排序是不稳定的。
● 复杂度分析
1、空间复杂度:快速排序、归并排序、计数排序和基数排序都需要开辟空间,插入排序、希尔排序、选择排序、堆排序、冒泡排序都不需要,空间复杂度为O(1)。
2、时间复杂度:
1)插入排序、希尔排序、选择排序、冒泡排序都为O(n^2),效率较低。选择排序效率最低,在最好情况下时间复杂度还是O(n^2);冒泡排序和插入排序相比较,插入排序较好(eg:0 2 1 3 4 5 6 7 8 9;插入排序一次完成,而冒泡排序需要冒两次),冒泡排序代价较大,并且插入在进行优化(希尔排序)后更能缩短排序时间。
2)堆排序、归并排序和快速排序都是O(n*lg(n))。
通常都看最坏的情况,但快速排序(存在更多优化)几乎不存在最坏情况,时间复杂度为O(n*lg(n))。
堆排序有一个缺点就是只能对数组进行排序,基数排序和计数排序都存在局限性(数据密集),归并排序的空间复杂度为O(n),而快速排序为O(lg(n)),综合可得快速排序最好。
【干货】
归并排序存在内排序和外排序。外排序其实就是指能够对内存之外(磁盘中)数据进行排序,对于大数据的文件,不能够直接加载到内存中进行排序,可以采取将文件划分成小文件,将小的文件加载到内存中进行排序,然后将排好序的数据进行重写,将两个有序的数据文件在重新排序,就能够排好大数据文件。依据以上思想可进行文件压缩的实现,有兴趣的可以自己试试。
 匿名组 这里可能用到几个不同的分组构造。通过括号内围绕的正...
匿名组 这里可能用到几个不同的分组构造。通过括号内围绕的正...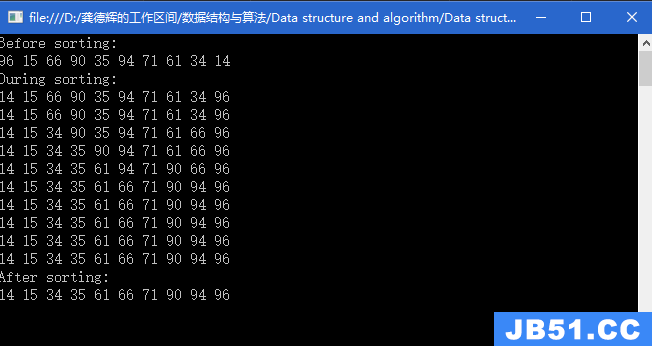 选择排序:从数组的起始位置处开始,把第一个元素与数组中其...
选择排序:从数组的起始位置处开始,把第一个元素与数组中其...