哈希表(散列表),是通过关键字key而直接访问在内存存储位置的一种数据结构,它就是 以空间换取时间。通过多开辟几个空间,来实现查找的高效率。
对于哈希表,我们并不是很陌生:在c语言学习阶段,给定一个字符串,查找第一个只出现过一次的字符;在数据结构 矩阵的高效转置方法中,计算原矩阵中每一列中有效数字的个数;在文件压缩项目(之后给出分析总结)中,计算中文件中各个字符出现的次数。
对于构造哈希表,有以下几种方法:
1)直接定址法:取关键字key的某个线性函数为散列地址
2)除留余数法:散列地址为,key模一个小于或者等于表长的数,如果key不是整数,可以通过各种途径转换,下边介绍~~
3)折叠法
4)平方取中法
5)随机数法
6)数学分析法
下边的几种方法,只需要知道就好~~重点掌握前两种~
对于直接定址法,给定一个key,就可以对应一个地址(这种比较适用于key值比较集中的情况,如果key值过于分散,就需要浪费很多空间)
对于除留余数法,不同的key有可能对应同一个散列地址。当多个key对应一个散列地址值时,这样就发生了冲突,这种冲突叫做哈希冲突或者哈希碰撞。
既然有了冲突,我们该如何解决冲突呢???这里就会有几种方法:
1)线性探测:对于一个给定的key,当有别的key值占了它的散列地址的位置,他就应该以线性方式去找下一个空位置
2)二次探测:实际是二次方探测,当发生冲突时,以二次方的方式去找下一个空位置。
3)开链法:
下边给出以上三种办法的图形解释:

为了防止哈希冲突,我们引入了负载因子这一概念,负载因子就是哈希表中元素的个数与哈希表的大小的比值就是负载因子。对于开放定址法,载荷因子是特别重要因素,应将其控制在0.7–0.8以下,查过0.8,查表时,CPU的缓存不命中。(cache的使用,解决了主存速度不足的问题。当CPU要读取一段数据时,先在cache中查找,如果找到了,说明命中;如果找不到,去主存中查找,然后根据调度算法将要读取的数据从主存调入cache)。。
我们通常将哈希表的大小设置为素数,这样也是可以防止冲突的。
如果哈希表中的数组的容量不是素数,假设要插入的元素是10,20,30,40,哈希表的大小是10,得到1种hash值,0。如果要插入的元素是3,6,9,12,而hash表的大小是9,得到3种hash值,0,3,6。这样,就导致冲突还是比较大的。。。。。此处证明不是很严谨,只是简单说明了一下。
为了达到自动扩大容量的作用,我们哈希表的底层用vector代替数组~
下边给出实现代码:
#pragma once
#include<iostream>
using namespace std;
#include<vector>
#include<string>
//开放地址法
namespace Open
{
enum Status
{
EMPTY,EXIST,DELETE
};
template<typename K,typename V>
struct KVNode
{
K _key;
V _value;
Status _status;//保存某个位置的状态
KVNode(const K& key = K(),const V& value = V())
:_key(key),_value(value),_status(EMPTY)
{}
};
template<typename K>
struct __GetK
{
size_t operator()(const K& key)
{
return key;
}
};
struct __GetStrK
{
static size_t BKDRHash(const char* str)
{
unsigned int seed = 131;// 31 131 1313 13131 131313
unsigned int hash = 0;
while(*str)
{
hash = hash * seed + (*str++);
}
return(hash & 0x7FFFFFFF);
}
size_t operator()(const string& str)
{
return BKDRHash(str.c_str());
}
};
template<typename K,typename V,typename GetK = __GetK<K>>
class HashTable
{
typedef KVNode<K,V> Node;
public:
HashTable()
:_size(0)
{
_tables.resize(2);
}
~HashTable()
{}
void Swap(HashTable<K,V,GetK> ht)
{
swap(_size,ht._size);
swap(_tables,ht._tables);
}
bool Insert(const K& key,const V& value)
{
_CheckCapacity();
int index = _GetIndex(key,value);
while(_tables[index]._status == EXIST)
{
if(_tables[index]._key == key)//要插入的值在原表中已经存在
{
return false;
}
++index;
if(index == _tables.size())
{
index = 0;
}
}
//找到合适的位置
_tables[index]._key = key;
_tables[index]._value = value;
_tables[index]._status = EXIST;//将状态改为存在
++_size;
}
Node* Find(const K& key,const V& value)
{
int index = _GetIndex(key,value);
int begin = index;
while(_tables[index]._key != key)
{
++index;
if(index == _tables.size())
{
index = 0;
}
if(index == begin)
{
return NULL;
}
}
//有可能是要删除的已经存在的元素
if(_tables[index]._status == EXIST)
{
return &_tables[index];
}
else
return NULL;
}
bool Remove(const K& key,const V& value)
{
if(_size == 0)
return false;
int index = _GetIndex(key,value);
int begin = index;
while(_tables[index]._status != EMPTY)
{
if(_tables[index]._key == key && _tables[index]._status == EXIST)
{
_tables[index]._status = DELETE;
--_size;
return true;
}
++index;
if(index == _tables.size())
{
index = 0;
}
if(index == begin)//已经遍历一圈
{
return false;
}
}
}
protected:
void _CheckCapacity()
{
if(_size*10 / _tables.size() >= 8)//保证查找效率
{
int newSize = _GetNewSize(_tables.size());
HashTable<K,GetK> hash;
hash._tables.resize(newSize);
for(size_t i = 0; i < _size; ++i)
{
if(_tables[i]._status == EXIST)
{
hash.Insert(_tables[i]._key,_tables[i]._value);
}
}
this->Swap(hash);
}
else
return;
}
int _GetIndex(const K& key,const V& value)
{
GetK getK;
return getK(key) % _tables.size();
}
int _GetNewSize(int num)
{
const int _PrimeSize= 28;
static const unsigned long _PrimeList[_PrimeSize] = {
53ul,97ul,193ul,389ul,769ul,1543ul,3079ul,6151ul,12289ul,24593ul,49157ul,98317ul,196613ul,393241ul,786433ul,1572869ul,3145739ul,6291469ul,12582917ul,25165843ul,50331653ul,100663319ul,201326611ul,402653189ul,805306457ul,1610612741ul,3221225473ul,4294967291ul
};
for(int i = 0; i < _PrimeSize; ++i)
{
if(_PrimeList[i] > num)
return _PrimeList[i];
}
}
protected:
vector<Node> _tables;
size_t _size;
};
}
void TestHashTableOpen()
{
Open::HashTable<int,int> ht1;//模板参数3是采用缺省的参数
int array1[] = {89,18,8,58,2,3,4,9,0};
for(int i = 0; i < sizeof(array1)/sizeof(array1[0]); ++i)
{
ht1.Insert(array1[i],0);
}
ht1.Remove(8,0);
ht1.Remove(1,0);
Open::HashTable<string,int,Open::__GetStrK> ht2;
char* array2[] = {"hello","world","sort","find","sort"};
for(int i = 0; i < sizeof(array2)/sizeof(array2[0]); ++i)
{
Open::KVNode<string,int>* node = ht2.Find(array2[i],0);
if(node)//结点已经存在
{
node->_value++;
}
else
{
ht2.Insert(array2[i],0);
}
}
}
//开链法
namespace Link
{
template<typename K,typename V>
struct KVNode
{
K _key;
V _value;
KVNode<K,V>* _next;
KVNode(const K& key = K(),const V& value = V())
:_key(key),_next(NULL)
{}
};
template<typename K>
struct __GetK
{
size_t operator()(const K& key)
{
return key;
}
};
template<>
struct __GetK<string>
{
static size_t BKDRHash(const char* str)
{
unsigned int seed = 131;// 31 131 1313 13131 131313
unsigned int hash = 0;
while(*str)
{
hash = hash * seed + (*str++);
}
return(hash & 0x7FFFFFFF);
}
size_t operator()(const string& str)
{
return BKDRHash(str.c_str());
}
};
template<typename K,V> Node;
public:
HashTable()
:_size(0)
{
_tables.resize(2);//初始化开辟2个空间
}
bool Insert(const K& key,const V& value)
{
//检查容量
_CheckCapacity();
int index = _GetIndex(key);
//先查找,看要插入的元素是否已经存在
if(Find(key))
{
return false;
}
//插入元素分两种情况
//1.插入的结点是第一个结点
//2.插入的结点不是第一个结点
Node* newNode = new Node(key,value);
newNode->_next = _tables[index];
_tables[index] = newNode;
++_size;
}
Node* Find(const K& key)
{
int index = _GetIndex(key);
Node* cur = _tables[index];
while(cur)
{
if(cur->_key == key)
return cur;
cur = cur->_next;
}
return NULL;
}
bool Remove(const K& key)
{
int index = _GetIndex(key);
//删除分3种情况
//1.删除第一个节点
//2.删除中间结点
//3.删除最后一个结点
Node* cur = _tables[index];
//记录要删除结点的上一个结点
Node* prev = NULL;
while(cur)
{
if(cur->_key == key)//找到要删除的结点
{
if(prev == NULL)//要删除的就是第一个结点
{
_tables[index] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
--_size;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}
protected:
int _GetIndex(const K& key)
{
GetK getK;
return getK(key) % _tables.size();
}
void _CheckCapacity()
{
if(_size == _tables.size())
{
int newSize = _GetNewSize(_size);//容量扩大
HashTable<K,GetK> tmp;
tmp._tables.resize(newSize);
vector<K> v;
Node* del = NULL;
//把所有元素放进vector中
for(size_t i = 0; i < _size; ++i)
{
//找到有存储元素的链
if(_tables[i] != NULL)
{
Node* cur = _tables[i];
while(cur)
{
//cur = _tables[i];
v.push_back(cur->_key);
cur = cur->_next;
}
//清理空间
cur = _tables[i];
while(cur)
{
del = cur;
cur = cur->_next;
delete del;
}
}
else
continue;
}
//将vector中的所有元素重新插入
for(size_t i = 0 ; i < v.size(); ++i)
{
tmp.Insert(v[i],0);
//v.pop_back();
}
//已经移动完成
this->_Swap(tmp);
}
}
int _GetNewSize(int num)
{
const int _PrimeSize= 28;
static const unsigned long _PrimeList[_PrimeSize] = {
53ul,4294967291ul
};
for(int i = 0; i < _PrimeSize; ++i)
{
if(_PrimeList[i] > num)
return _PrimeList[i];
}
}
void _Swap(HashTable<K,GetK> ht)
{
swap(ht._tables,_tables);
swap(ht._size,_size);
}
protected:
vector<Node* > _tables;
size_t _size;
};
}
void TestHashTableLink()
{
Link::HashTable<int,int> ht1;
int array1[] = {89,21,53,12,0);
}
ht1.Remove(4);
ht1.Remove(12);
Link::HashTable<string,int> ht2;
char* array2[] = {"hello","yang","hello","wang","zip","huffman"};
for(int i = 0; i < sizeof(array2)/sizeof(array2[0]); ++i)
{
Link::KVNode<string,int>* ret = ht2.Find(array2[i]);
if(!ret)
ht2.Insert(array2[i],0);
}
ht2.Remove("hello");
ht2.Remove("sort");
}
上边这段代码,我们既实现了线性探测法,也实现了开链法。使用命名空间来防止名字冲突。使用仿函数达到将字符串转换成整形来取模。 在线性探测法中,对哈希表增容过程中,直接将原来的元素插入新的哈希表的对应位置;而在开链法中,将原来的所有节点放进一个vector中,然后将vector中所有元素重新插入新的哈希表的对应位置~~ 关于哈希表,未完待续~
 匿名组 这里可能用到几个不同的分组构造。通过括号内围绕的正...
匿名组 这里可能用到几个不同的分组构造。通过括号内围绕的正...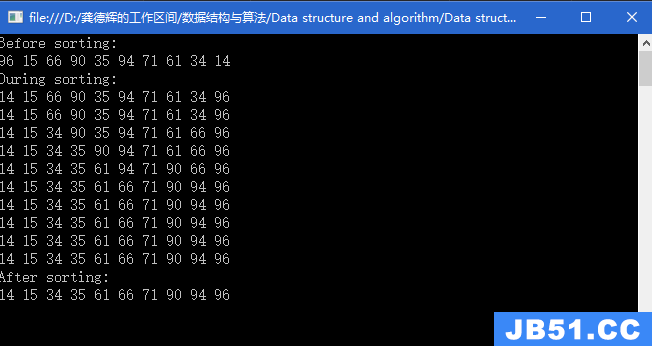 选择排序:从数组的起始位置处开始,把第一个元素与数组中其...
选择排序:从数组的起始位置处开始,把第一个元素与数组中其...