首先我们一般求子串的位置的时候,我们可以使用这样的方法
/* *功能:这个是定长的串的顺序存储 *时间:2015年7月15日17:16:01 *文件:sstring.h *作者:cutter_point */
#ifndef sstRING_H
#define sstRING_H
#define MAXSTRLEN 255
class sstring
{
unsigned char* ch; //我们的串的顺序存储空间
unsigned int length; //我们有效元素的个数
public:
sstring(){}
sstring(unsigned char c[],int lenth){ ch = new unsigned char[MAXSTRLEN + 1]; ch = c; this->length = lenth; } //申请堆存储空间
//一个匹配子串的算法实现
/************************************************************************/
/* 返回子串T在主串S中第pos位置之后的位置,若不存在,返回0 */
/************************************************************************/
int BFindex(sstring T,int pos);
//得到这个字符串的长度
unsigned int getLength();
unsigned char* getCh();
//设置相应的值
void setCh(unsigned char *c) { ch = c; }
void setLength(unsigned int len) { length = len; }
//unsigned char* getCh() { return ch; }
//unsigned int getLength() { return length; }
};
#endif
实现这个类
/* *功能:这个是定长的串的顺序存储 *时间:2015年7月15日17:16:01 *文件:sstring.h *作者:cutter_point */
#include "sstring.h"
//得到这个字符串的长度
//int length(); 我们不知道这个数组的终止条件是不能求出来这个数组有多长的
/* int sstring::length() { return 0; } */
//得到这个字符串的长度
//int getLength();
unsigned int sstring::getLength()
{
return this->length;
}
//获取我们的字符串
//char* getCh();
unsigned char* sstring::getCh()
{
return this->ch;
}
//一个匹配子串的算法实现
/************************************************************************/
/* 返回子串T在主串S中第pos位置之后的位置,若不存在,返回0 */
/************************************************************************/
//int BFindex(sstring T,int pos);
int sstring::BFindex(sstring T,int pos)
{
//首先我们用两个游标参数来计数我们遍历的位置
int i = pos,j = 1;
//然后我们用两个unsigned char 的指针来指向两个我们来比较的字符串
unsigned char *p1 = this->getCh(),*p2 = T.getCh();
//开始循环比较,当第一个匹配到了的时候,我们就接着比较后面的,如果中间出错,那么我们回头从新比较主串的下一个元素作为开始
//记住我么的字符串的第一个元素时不存放东西的,我们从下标为1的那个开始存放包括1
while (i <= this->getLength() && j <= T.getLength())
{
//如果匹配到了我们就一起匹配第二个元素
if (p1[i] == p2[j])
{
++i;
++j;
}
else
{
//否则我们就回到起点的第二个元素和子串进行比较
i = i - j + 2; //下一个元素
j = 1; //子串从头开始
}
}
//最后看看是不是有完全匹配到的
if (j > T.getLength())
return i - T.getLength(); //获取这个位置的地方
else
return 0;
}
这样,我们已经可以用来进行常规的字符串的匹配了
这种匹配模式的时间复杂度为:O(n*m)
我们可以改进我们的算法,我们采用kmp算法
/*
*功能:使用kmp算法对字符串进行匹配,
* 1、一般情况下我们主串和模式串匹配到了一定程度,比如匹配到了5个(主模长度都比5大),但是第6个字符不相等
那么我们接下来需要匹配的是在主串的什么地方开始,也可能是匹配的5个中后面有几个正好是模式串的开头,那么我们如何开始下一个子串的匹配
2、当主串的第i个字符与模式串的第j个字符匹配不等的时候,假设此时应该和模式中第k(k<j)个字符继续比较
3、我们已经得到匹配的字符串是k======================================从模式第k个开始比较,k-1就是开始新的匹配的时候前面不用比较的个数
4、j=================================模式串第j个字符失配(前面那次比较得到的结果,下一次就是用到k的那次)
5、i=================================主串第i个字符失配
6、我们先假设p:1到p:k-1是模式串,然后s:1到s:m是主串
7、模式串中后半部分和主串前面重合,不需要接下来匹配的部分是 { p:j-k+1 。。。 p:j-1 } 这个就是我们模式串中和主串后部分重合的地方
j-k+1这个就是我们模式串中前面不用再和主串比较的起始位置,其实就是把失配的地方前移后面不用比较的个数j-(k-1)
8、主串中我们也吧他前移k-1个字符,也就是我们不用比较的那些字符起始位置 { s:i-(k-1)。。。s:i-1 }
9、由上可得模式串中已经不需要和主串比较的部分也就是 { p:1。。。p:k-1 } 和 { s:i-(k-1)。。。s:i-1 } 相等
10、而{ s:i-(k-1)。。。s:i-1 } 就是我们后面不用比较的部分又和 { p:j-k+1 。。。 p:j-1 }相等
11、那么 { p:j-k+1 。。。 p:j-1 } 和 { p:1。。。p:k-1 } 相等
12、所以模式串满足11步的子串的时候,我们只需要把主串在不相等的地方开始,而子串只需要从第k个字符开始和主串的第i个字符开始比较
13、那么我们可以根据j的值来算k的值,也就是下一个k的值是next[j],我们让next[j] = k - 1;
14、计算k的公式就是 { p:j-k+1 。。。 p:j-1 } == { p:1。。。p:k-1 } 并且 1 < next[j] < j 取最大值(也就是可以不用比较的最大值),并且{ p:j-k+1 。。。 p:j-1 } == { p:1。。。p:k-1 }两个的序号不能一样
15、-----------------------------------如何获取对应{ p:j-k+1 。。。 p:j-1 } == { p:1。。。p:k-1 }的k值-------------------------------------------------------------------------------------------------------------------------
16、我们使next[j] = k,用模式串的匹配条件和1 < next[j] < j 来取得k值的
17、我们假设next[j] = k可以递推出下一个next[j+1]的值,通过p:k与p:j的值是否相等
18、这个就是把模式串当做主串和模式串进行比较,寻找相同的部分
19、我们模式串的next数据和我们要匹配的主串无关,只和我们的模式串自己相关
*时间:2015年7月18日19:12:23,2015年7月26日16:37:17
*文件:kmp.h
*作者:cutter_point
*/
#ifndef KMP_H
#define KMP_H
#include "sstring.h"
class KmpString : public sstring
{
int *next;
public:
KmpString(unsigned char *css,unsigned int len) :sstring(css,len) {}
int index_KMP(sstring T,unsigned int pos);
void get_next(sstring T);
int* getNext() { return next; }
};
#endif
实现我们的类
/* *功能:使用kmp算法对字符串进行匹配, * 1、一般情况下我们主串和模式串匹配到了一定程度,比如匹配到了5个(主模长度都比5大),但是第6个字符不相等 那么我们接下来需要匹配的是在主串的什么地方开始,也可能是匹配的5个中后面有几个正好是模式串的开头,那么我们如何开始下一个子串的匹配 2、当主串的第i个字符与模式串的第j个字符匹配不等的时候,假设此时应该和模式中第k(k<j)个字符继续比较 3、我们已经得到匹配的字符串是k======================================从模式第k个开始比较,k-1就是开始新的匹配的时候前面不用比较的个数 4、j=================================模式串第j个字符失配(前面那次比较得到的结果,下一次就是用到k的那次) 5、i=================================主串第i个字符失配 6、我们先假设p:1到p:k-1是模式串,然后s:1到s:m是主串 7、模式串中后半部分和主串前面重合,不需要接下来匹配的部分是 { p:j-k+1 。。。 p:j-1 } 这个就是我们模式串中和主串后部分重合的地方 j-k+1这个就是我们模式串中前面不用再和主串比较的起始位置,其实就是把失配的地方前移后面不用比较的个数j-(k-1) 8、主串中我们也吧他前移k-1个字符,也就是我们不用比较的那些字符起始位置 { s:i-(k-1)。。。s:i-1 } 9、由上可得模式串中已经不需要和主串比较的部分也就是 { p:1。。。p:k-1 } 和 { s:i-(k-1)。。。s:i-1 } 相等 10、而{ s:i-(k-1)。。。s:i-1 } 就是我们后面不用比较的部分又和 { p:j-k+1 。。。 p:j-1 }相等 11、那么 { p:j-k+1 。。。 p:j-1 } 和 { p:1。。。p:k-1 } 相等 12、所以模式串满足11步的子串的时候,我们只需要把主串在不相等的地方开始,而子串只需要从第k个字符开始和主串的第i个字符开始比较 13、那么我们可以根据j的值来算k的值,也就是下一个k的值是next[j],我们让next[j] = k - 1; 14、计算k的公式就是 { p:j-k+1 。。。 p:j-1 } == { p:1。。。p:k-1 } 并且 1 < next[j] < j 取最大值(也就是可以不用比较的最大值),并且{ p:j-k+1 。。。 p:j-1 } == { p:1。。。p:k-1 }两个的序号不能一样 15、-----------------------------------如何获取对应{ p:j-k+1 。。。 p:j-1 } == { p:1。。。p:k-1 }的k值------------------------------------------------------------------------------------------------------------------------- 16、我们使next[j] = k,用模式串的匹配条件和1 < next[j] < j 来取得k值的 17、我们假设next[j] = k可以递推出下一个next[j+1]的值,通过p:k与p:j的值是否相等 18、这个就是把模式串当做主串和模式串进行比较,寻找相同的部分 19、我们模式串的next数据和我们要匹配的主串无关,只和我们的模式串自己相关 *时间:2015年7月18日20:42:43,2015年7月26日16:37:25 *文件:kmp.cpp *作者:cutter_point */
#include "kmp.h"
#include <iostream>
//void get_next(sstring T);
void KmpString::get_next(sstring T) //获取next列表
{
std::cout << T.getCh() << std::endl;
//这来两个数j代表着是模式串中的位置,i用来计数在模式串中的遍历位置,防止访问越界
//首先我们初始化我们的next的第一个数和我们的起始比较的位置
/* unsigned char *t = T.getCh(); int j = 2; this->next[j] = 0; int i = next[j]; //这个就是我们的上一个我们求next[j+1]的时候的next[j] next[2] = 1; while (j <= this->getLength()) { if (t[j] == t[i]) { ++i; ++j; //集体向后移一位 //如果下一个字符相等的话,也就是p:k和p:j相等 next[j] = i + 1; } else { i = next[i]; //这个就是我们的第p:k和p:j不相等,那么我们就求得next[k]的值,作为我们新的比较起点 } } */
//初始化我们的next
this->next = new int[20]{0};
//我们首先设定一个参数遍历主串,然后设定一个参数遍历子串
int j = 1,i = 0; //子串的那个还没开始比较是为0
this->next[1] = 0; //第一个,设定为0表示主节点是第一个的时候也就是j = 1的时候,没哟从复的地方
unsigned char *t = T.getCh(); //得到我们的字符串
if (T.getLength() > 1) //首先我们传进来要进行求比较位置的参数不能为空,也就是长度大于0
{
//循环遍历主串
while (j < T.getLength())
{
//判断子串的位置是否是0从新开始,或者我们主串的位置和子串的位置比较
if (i == 0 || t[j] == t[i])
{
//如果是第一个或者匹配相等
++j; //主串
++i; //子串
this->next[j] = i; //我们把主串的和子串匹配的位置记住
}
else
{
//如果这个p:j和p:k不相等,也就是t[j] != t[i]不相等的时候
i = next[i];
}
}
}
}
/* 利用模式T的next的值,求T在S主串中第pos个字符之后的位置 */
int KmpString::index_KMP(sstring T,unsigned int pos)
{
int i = pos,j = 1; //第一个是我们主串开始的位置,后面是我们模式串开始的位置
unsigned char *s = this->getCh();
unsigned char *t = T.getCh();
while (i <= this->getLength() && j <= T.getLength())
{
//在长度范围内
if (j == 0 || s[i] == t[j])
{
++i;
++j;
}
else
{
j = next[j];
}
}
//循环结束之后我们判断一下是遍历到了最后的没有找到,还是找到了
if (j > T.getLength()) //说明匹配到了最后的位置
return i - T.getLength();
else
return 0;
}
我们的主函数
/*
*功能:串的所有执行策测试
*时间:2015年7月15日17:16:01,2015年7月21日20:33:10,2015年7月26日16:37:31
*文件:sstring.h
*作者:cutter_point
*/
#include <iostream>
#include "kmp.h"
#include "sstring.h"
using namespace std;
int main()
{
unsigned char c[] = " acabaabaabcacaabc";
unsigned char c2[] = " abaabcac";
sstring T;
T.setCh(c2);
T.setLength(8);
KmpString *ks = new KmpString(c,16);
ks->get_next(T);
int *p = ks->getNext();
for (int i = 0; i < 21; ++i)
{
cout << *(p + i) << "\t";
}
cout << endl;
cout << ks->index_KMP(T,1) << " hahaah " << endl;
return 0;
}
/*
int main()
{
unsigned char ch[] = {' ','a','b','c','b'};
unsigned char ch2[] = {' ','c'};
int lengch = 14;
int lengch2 = 3;
sstring *s = new sstring(ch,lengch);
sstring t;
t.setCh(ch2);
t.setLength(lengch2);
cout<<s->BFindex(t,1);
return 0;
}
*/
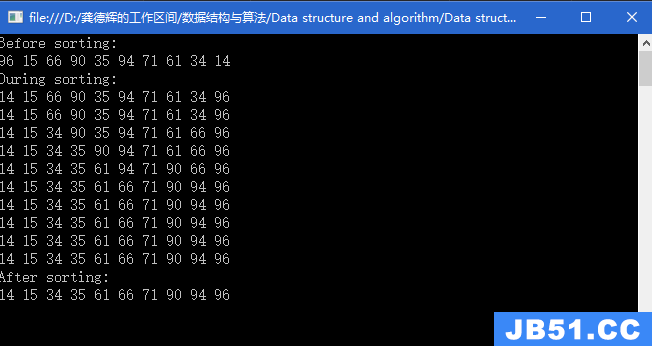
输出结果: