这篇文章给大家分享的是有关Redis中的LRU算法有什么用的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
Redis是基于内存存储的key-value数据库,我们知道内存虽然快但空间小,当物理内存达到上限时,系统就会跑的很慢,这是因为swap机制会将部分内存的数据转移到swap分区中,通过与swap的交换保证系统继续运行;但是swap属于硬盘存储,速度远远比不上内存,尤其是对于Redis这种QPS非常高的服务,发生这种情况是无法接收的。(注意如果swap分区内存也满了,系统就会发生错误!)【相关推荐:Redis视频教程】
Linux操作系统可以通过free -m查看swap大小:\

因此如何防止Redis发生这种情况非常重要(面试官问到Redis几乎没有不问这个知识点的)。
2、maxmemory配置
Redis针对上述问题提供了maxmemory配置,这个配置可以指定Redis存储器的最大数据集,通常情况都是在redis.conf文件中进行配置,也可以运行时使用CONfig SET命令进行一次性配置。
redis.conf文件中的配置项示意图:\

默认情况maxmemory配置项并未启用,Redis官方介绍64位操作系统默认无内存限制,32位操作系统默认3GB隐式内存配置,如果maxmemory 为0,代表内存不受限。
因此我们在做缓存架构时,要根据硬件资源+业务需求做合适的maxmemory配置。
3、内存达到maxmemory怎么办
很显然配置了最大内存,当maxmemory达到了最大上限之后Redis不可能不干活了,那么Redis是怎么来处理这个问题的呢?这就是本文的重点,Redis 提供了maxmemory-policy淘汰策略(本文只讲述LRU不涉及LFU,LFU在下一篇文章讲述),对满足条件的key进行删除,辞旧迎新。
maxmemory-policy淘汰策略:
noeviction: 当达到内存限制并且客户端尝试执行可能导致使用更多内存的命令时返回错误,简单来说读操作仍然允许,但是不准写入新的数据,del(删除)请求可以。
allkeys-lru: 从全体key中,通过lru(Least Recently Used - 最近最少使用)算法进行淘汰
allkeys-random: 从全体key中,随机进行淘汰
volatile-lru: 从设置了过期时间的全部key中,通过lru(Least Recently Used - 最近最少使用)算法进行淘汰,这样可以保证未设置过期时间需要被持久化的数据,不会被选中淘汰
volatile-ttl: 从设置了过期时间的全部key中,通过比较key的剩余过期时间TTL的值,TTL越小越先被淘汰
还有volatile-lfu/allkeys-lfu这个留到下文一起探讨,两个算法不一样!
random随机淘汰只需要随机取一些key进行删除,释放内存空间即可;ttl过期时间小先淘汰也可以通过比较ttl的大小,将ttl值小的key进行删除,释放内存空间即可。
那么LRU是怎么实现的呢?Redis又是如何知道哪个key最近被使用了,哪个key最近没有被使用呢?
4、LRU算法实现
我们先用Java的容器实现一个简单的LRU算法,我们使用ConcurrentHashMap做key-value结果存储元素的映射关系,使用ConcurrentLinkedDeque来维持key的访问顺序。
LRU实现代码:
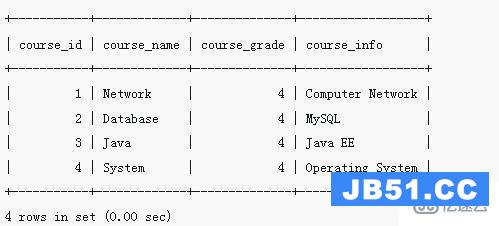
package com.lizba.redis.lru; import java.util.Arrays; import java.util.List; import java.util.concurrent.ConcurrentHashMap; import java.util.concurrent.ConcurrentLinkedDeque; /** * <p> * LRU简单实现 * </p> * * @Author: Liziba * @Date: 2021/9/17 23:47 */ public class SimpleLru { /** 数据缓存 */ private ConcurrentHashMap<String, Object> cacheData; /** 访问顺序记录 */ private ConcurrentLinkedDeque<String> sequence; /** 缓存容量 */ private int capacity; public SimpleLru(int capacity) { this.capacity = capacity; cacheData = new ConcurrentHashMap(capacity); sequence = new ConcurrentLinkedDeque(); } /** * 设置值 * * @param key * @param value * @return */ public Object setValue(String key, Object value) { // 判断是否需要进行LRU淘汰 this.maxMemoryHandle(); // 包含则移除元素,新访问的元素一直保存在队列最前面 if (sequence.contains(key)) { sequence.remove(); } sequence.addFirst(key); cacheData.put(key, value); return value; } /** * 达到最大内存,淘汰最近最少使用的key */ private void maxMemoryHandle() { while (sequence.size() >= capacity) { String lruKey = sequence.removeLast(); cacheData.remove(lruKey); System.out.println("key: " + lruKey + "被淘汰!"); } } /** * 获取访问LRU顺序 * * @return */ public List<String> getAll() { return Arrays.asList(sequence.toArray(new String[] {})); } }复制代码
测试代码:
package com.lizba.redis.lru; /** * <p> * 测试最近最少使用 * </p> * * @Author: Liziba * @Date: 2021/9/18 0:00 */ public class TestSimpleLru { public static void main(String[] args) { SimpleLru lru = new SimpleLru(8); for (int i = 0; i < 10; i++) { lru.setValue(i+"", i); } System.out.println(lru.getAll()); } }复制代码
测试结果:\

从上数的测试结果可以看出,先加入的key0,key1被淘汰了,最后加入的key也是最新的key保存在sequence的队头。
通过这种方案,可以很简单的实现LRU算法;但缺点也十分明显,方案需要使用额外的数据结构来保存key的访问顺序,这样会使Redis内存消耗增加,本身用来优化内存的方案,却要消耗不少内存,显然是不行的。
5、Redis的近似LRU
针对这种情况,Redis使用了近似LRU算法,并不是完完全全准确的淘汰掉最近最不经常使用的key,但是总体的准确度也可以得到保证。
近似LRU算法非常简单,在Redis的key对象中,增加24bit用于存储最近一次访问的系统时间戳,当客户端对Redis服务端发送key的写入相关请求时,发现内存达到maxmemory,此时触发惰性删除;Redis服务通过随机采样,选择5个满足条件的key(注意这个随机采样allkeys-lru是从所有的key中随机采样,volatile-lru是从设置了过期时间的所有key中随机采样),通过key对象中记录的最近访问时间戳进行比较,淘汰掉这5个key中最旧的key;如果内存仍然不够,就继续重复这个步骤。
注意,5是Redis默认的随机采样数值大小,它可以通过redis.conf中的maxmemory_samples进行配置:\

针对上述的随机LRU算法,Redis官方给出了一张测试准确性的数据图:
最上层浅灰色表示被淘汰的key,图一是标准的LRU算法淘汰的示意图
中间深灰色层表示未被淘汰的旧key
最下层浅绿色表示最近被访问的key

在Redis 3.0 maxmemory_samples设置为10的时候,Redis的近似LRU算法已经非常的接近真实LRU算法了,但是显然maxmemory_samples设置为10比maxmemory_samples 设置为5要更加消耗cpu计算时间,因为每次采样的样本数据增大,计算时间也会增加。
Redis3.0的LRU比Redis2.8的LRU算法更加准确,是因为Redis3.0增加了一个与maxmemory_samples相同大小的淘汰池,每次淘汰key的时候,先与淘汰池中等待被淘汰的key进行比较,最后淘汰掉最老旧的key,其实就是被选中淘汰的key放到一起再比较一下,淘汰其中最旧的。
6、存在问题
LRU算法看似比较好用,但是也存在不合理的地方,比如A和B两个key,在发生淘汰时的前一个小时前同一时刻添加到Redis,A在前49分钟被访问了1000次,但是后11分钟没有被访问;B在这一个小时内仅仅第59分钟被访问了1次;此时如果使用LRU算法,如果A、B均被Redis采样选中,A将会被淘汰很显然这个是不合理的。
针对这种情况Redis 4.0添加了LFU算法,(Least frequently used) 最不经常使用,这种算法比LRU更加合理。
感谢各位的阅读!关于“Redis中的LRU算法有什么用”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!