最近对爬虫很感兴趣,稍微研究了一下,利用HtmlAgilityPack制作了一个十分简单的爬虫,这个简易爬虫只能获取静态页面的Html
HtmlAgilityPack简介
HtmlAgilityPack是一个解析速度十分快,并且开源的Html解析工具,并且HtmlAgilityPack支持使用Xpath解析Html,能够帮助我们解析Html文档就像解析Xml文档一样轻松、方便。
C#安装HtmlAgilityPack
- 如果VS安装有Nuget,在Nuget直接搜索安装即可。
- 下载后解压缩后有3个文件,这里只需要将其中的HtmlAgilityPack.dll、HtmlAgilityPack.xml引入解决方案中即可使用
实例(获取某页面图片)
加载HTML页面
//从网页中加载
string url = "https://www.bilibili.com";
HtmlWeb web = new HtmlWeb();
HtmlDocument hd = web.Load(url);
利用WebClient写一个图片下载器
需要using System.Net和using System.IO
/// <summary>
/// 图片下载器
/// </summary>
public class ImgDownloader
{
/// <summary>
/// 下载图片
/// </summary>
/// <param name="webClient"></param>
/// <param name="url">图片url</param>
/// <param name="folderPath">文件夹路径</param>
/// <param name="fileName">图片名</param>
public static void DownloadImg(WebClient webClient,string url,string folderPath,string fileName)
{
//如果文件夹不存在,则创建一个
if (!Directory.Exists(folderPath))
{
Directory.CreateDirectory(folderPath);
}
//判断路径是否完整,补全不完整的路径
if (url.IndexOf("https:") == -1 && url.IndexOf("http:") == -1)
{
url = "https:" + url;
}
//下载图片
try
{
webClient.DownloadFile(url,folderPath + fileName);
Console.WriteLine(fileName + "下载成功");
}
catch (Exception ex)
{
Console.Write(ex.Message);
Console.WriteLine(url);
}
}
}
通过Xpath获取img标签中的图片
string imgPath = "//img";//选择img
int imgNum = 0;//图片编号
//获取img标签中的图片
foreach (HtmlNode node in hd.DocumentNode.SelectNodes(imgPath))
{
if (node.Attributes["src"] != null)
{
string imgUrl = node.Attributes["src"].Value.ToString();
if (imgUrl != "" && imgUrl != " ")
{
imgNum++;
//生成文件名,自动获取后缀
string fileName = imgNum + imgUrl.Substring(imgUrl.LastIndexOf("."));
ImgDownloader.DownloadImg(wc,imgUrl,"images/",fileName);
}
}
}
通过Xpath获取背景图
//获取背景图
string bgImgPath = "//*[@style]";//选择具有style属性的节点
foreach (HtmlNode node in hd.DocumentNode.SelectNodes(bgImgPath))
{
if (node.Attributes["style"].Value.Contains("background-image:url"))
{
imgNum++;
string bgImgUrl = node.Attributes["style"].Value;
bgImgUrl = Regex.Match(bgImgUrl,@"(?<=\().+?(?=\))").Value;//读取url()的内容
//Console.WriteLine(bgImgUrl);
//生成文件名,自动获取后缀
string fileName = imgNum + bgImgUrl.Substring(bgImgUrl.LastIndexOf("."));
ImgDownloader.DownloadImg(wc,bgImgUrl,"images/bgcImg/",fileName);
}
}
完整代码
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Net;
using System.IO;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
namespace WebCrawlerDemo
{
class Program
{
static void Main(string[] args)
{
WebClient wc = new WebClient();
string url = "https://www.bilibili.com";
HtmlWeb web = new HtmlWeb();
HtmlDocument hd = web.Load(url);//下载html页面
string imgPath = "//img";//选择img
int imgNum = 0;//图片编号
//获取img标签中的图片
foreach (HtmlNode node in hd.DocumentNode.SelectNodes(imgPath))
{
if (node.Attributes["src"] != null)
{
string imgUrl = node.Attributes["src"].Value.ToString();
if (imgUrl != "" && imgUrl != " ")
{
imgNum++;
//生成文件名,自动获取后缀
string fileName = imgNum + imgUrl.Substring(imgUrl.LastIndexOf("."));
ImgDownloader.DownloadImg(wc,fileName);
}
}
}
//获取背景图
string bgImgPath = "//*[@style]";//选择具有style属性的节点
foreach (HtmlNode node in hd.DocumentNode.SelectNodes(bgImgPath))
{
if (node.Attributes["style"].Value.Contains("background-image:url"))
{
imgNum++;
string bgImgUrl = node.Attributes["style"].Value;
bgImgUrl = Regex.Match(bgImgUrl,@"(?<=\().+?(?=\))").Value;//读取url()的内容
//生成文件名,自动获取后缀
string fileName = imgNum + bgImgUrl.Substring(bgImgUrl.LastIndexOf("."));
ImgDownloader.DownloadImg(wc,fileName);
}
}
Console.WriteLine("----------END----------");
Console.ReadKey();
}
}
/// <summary>
/// 图片下载器
/// </summary>
public class ImgDownloader
{
/// <summary>
/// 下载图片
/// </summary>
/// <param name="webClient"></param>
/// <param name="url">图片url</param>
/// <param name="folderPath">文件夹路径</param>
/// <param name="fileName">图片名</param>
public static void DownloadImg(WebClient webClient,string fileName)
{
//如果文件夹不存在,则创建一个
if (!Directory.Exists(folderPath))
{
Directory.CreateDirectory(folderPath);
}
//判断路径是否完整,补全不完整的路径
if (url.IndexOf("https:") == -1 && url.IndexOf("http:") == -1)
{
url = "https:" + url;
}
//下载图片
try
{
webClient.DownloadFile(url,folderPath + fileName);
Console.WriteLine(fileName + "下载成功");
}
catch (Exception ex)
{
Console.Write(ex.Message);
Console.WriteLine(url);
}
}
}
}
 项目中经常遇到CSV文件的读写需求,其中的难点主要是CSV文件...
项目中经常遇到CSV文件的读写需求,其中的难点主要是CSV文件... 简介 本文的初衷是希望帮助那些有其它平台视觉算法开发经验的...
简介 本文的初衷是希望帮助那些有其它平台视觉算法开发经验的... 这篇文章主要简单记录一下C#项目的dll文件管理方法,以便后期...
这篇文章主要简单记录一下C#项目的dll文件管理方法,以便后期...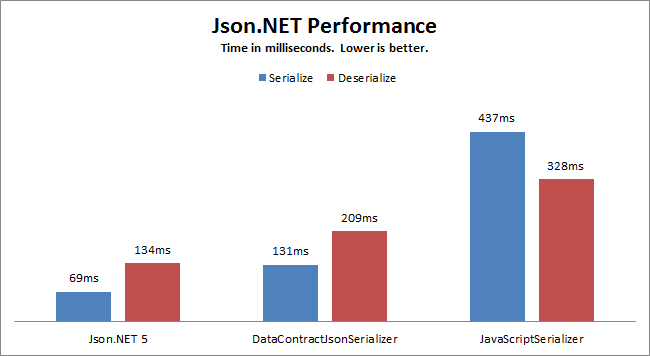 在C#中的使用JSON序列化及反序列化时,推荐使用Json.NET——...
在C#中的使用JSON序列化及反序列化时,推荐使用Json.NET——...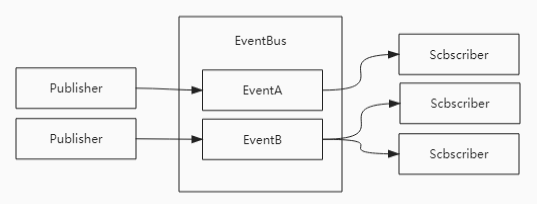 事件总线是对发布-订阅模式的一种实现,是一种集中式事件处理...
事件总线是对发布-订阅模式的一种实现,是一种集中式事件处理... 通用翻译API的HTTPS 地址为https://fanyi-api.baidu.com/api...
通用翻译API的HTTPS 地址为https://fanyi-api.baidu.com/api...