我正在编写一个代码,可以扫描多个.docx文件中的关键字,然后将整个句子输出,直到换行符.
这个函数效果很好,我得到包含关键字的每个句子,直到换行符.
我的问题:
当我不希望文本直到第一个换行符时,我的RegEx如何看起来像,但文本到第二个换行符?也许用正确的量词?我没有得到它的工作.
我的模式:“.*”“keyword”“.*”
Main.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Text.RegularExpressions;
using Xceed.Words.NET;
public class Class1
{
static void Main(string[] args)
{
String searchParam = @".*" + "thiskeyword" + ".*";
List<String> docs = new List<String>();
docs.Add(@"C:\Users\itsmemario\Desktop\project\test.docx");
for (int i = 0; i < docs.Count; i++)
{
Suche s1 = new Suche(docs[i],searchParam);
s1.SearchEngine(docs[i],searchParam);
}
}
}
Suche.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Text.RegularExpressions;
using Xceed.Words.NET;
public class Suche
{
String path;
String stringToSearchFor;
List<String> searchResult = new List<String>();
public Suche(String path,String stringToSearchFor)
{
this.path = path;
this.stringToSearchFor = stringToSearchFor;
}
public void SearchEngine(String path,String stringToSearchFor)
{
using (var document = DocX.Load(path))
{
searchResult = document.FindUniqueByPattern(stringToSearchFor,RegexOptions.IgnoreCase);
if (searchResult.Count != 0)
{
WriteList(searchResult);
}
else
{
Console.WriteLine("Text does not contain keyword!");
}
}
}
public void WriteList(List<String> list)
{
for (int i = 0; i < list.Count; i++)
{
Console.WriteLine(list[i]);
Console.WriteLine("\n");
}
}
}
预期的产量就像
"*LINEBREAK* Theres nothing nicer than a working filter for keywords. *LINEBREAK*"
解决方法
您不能使用document.FindUniqueByPattern DocX方法来跨行匹配,因为它只搜索单个段落.见
this source code,即foreach(段落中的段落p).
您可以获取document.Text属性,或将所有段落文本合并为一个并在整个文本中搜索.删除searchResult = document.FindUniqueByPattern(stringToSearchFor,RegexOptions.IgnoreCase);线和使用
var docString = string.Join("\n",document.Paragraphs.Select(p => p.text));
// var docString = string.Join("\n",document.Paragraphs.SelectMany(p => p.MagicText.Select(x => x.text)));
searchResult = Regex.Matches(docString,$@".*{Regex.Escape(stringToSearchFor)}.*\n.*",RegexOptions.IgnoreCase)
.Cast<Match>()
.Select(x => x.Value)
.ToList();
 项目中经常遇到CSV文件的读写需求,其中的难点主要是CSV文件...
项目中经常遇到CSV文件的读写需求,其中的难点主要是CSV文件... 简介 本文的初衷是希望帮助那些有其它平台视觉算法开发经验的...
简介 本文的初衷是希望帮助那些有其它平台视觉算法开发经验的... 这篇文章主要简单记录一下C#项目的dll文件管理方法,以便后期...
这篇文章主要简单记录一下C#项目的dll文件管理方法,以便后期...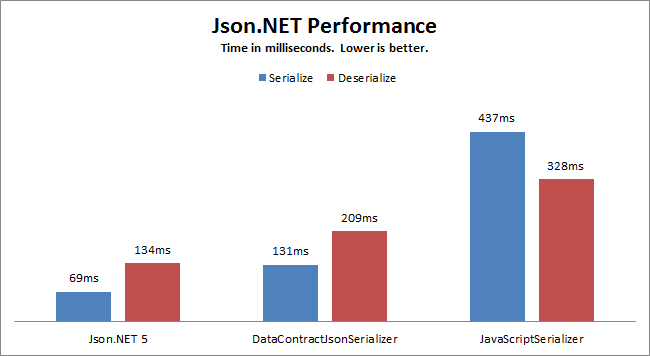 在C#中的使用JSON序列化及反序列化时,推荐使用Json.NET——...
在C#中的使用JSON序列化及反序列化时,推荐使用Json.NET——...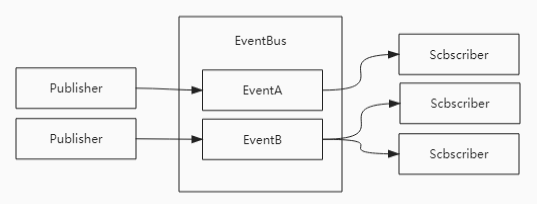 事件总线是对发布-订阅模式的一种实现,是一种集中式事件处理...
事件总线是对发布-订阅模式的一种实现,是一种集中式事件处理... 通用翻译API的HTTPS 地址为https://fanyi-api.baidu.com/api...
通用翻译API的HTTPS 地址为https://fanyi-api.baidu.com/api...