补上之前的坑,单机版搭完了,今天来搭伪分布式版的Hadoop环境,单机版Hadoop最大的特点是没有HDFS(Hadoop Distributed File System)就是Hadoop分布式文件系统,其实是将一个大文件分成若干块保存在不同服务器的多个节点中。通过联网让用户感觉像是在本地一样查看文件,为了降低文件丢失造成的错误,它会为每个小文件复制多个副本(默认为三个),以此来实现多机器上的多用户分享文件和存储空间。
伪分布式Hadoop具备了Hadoop的所有功能,在单机上模拟分布式环境,包括:
HDFS 主节点:NameNode 主节点副本:SecondaryNameNode 数据节点:DataNode
Yarn:容器,用于运行MapReduce程序 主节点:ResourceManager 从节点:NodeManager
之前博主单机版已经搭建完了,有没搭建的可以去阿里云ECS服务器CentOS7.3搭建单机版Hadoop环境看看
那么我们先cd进hadoop的安装目录看看有什么东西
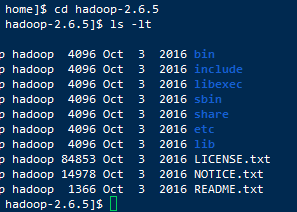
bin:存放的是我们用来实现管理和使用hadoop的脚本集合,我们对Hadoop进行操作就要使用bin目录下的脚本
sbin: 存放的是我们管理脚本的所在目录,重要是对HDFS和Yarn的各种开启和关闭和单线程开启和守护
etc:存放Hadoop的配置文件
lib:存放Hadoop运行时依赖的jar包
include:存放对外提供的编程库的头文件
share:存放Hadoop各个模块编译后的jar包
伪分布式的配置如下

配置文件在etc目录下,cd到etc/hadoop/目录下,首先我们在hadoop-env.sh下添加jdk的环境变量
echo $JAVA_HOME //得到你的jdk路径 vim hadoop-env.sh export JAVA_HOME = 你的jdk路径
之后配置HDFS
vim hdfs-site.xml <configuration> <!--配置HDFS的副本,冗余度--> <property> <name>dfs.replication</name> <value>1</value> </property> <!--配置HDFS的权限--> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
然后是核心配置文件core-site.xml的配置
vim core-site.xml <configuration> <!--配置NameNode的主机地址--> <property> <name>fs.defaultFS</name> <value>localhost:9000</value> //本机ip </property> <property> <!--配置DataNode数据的目录--> <name>hadoop.tmp.dir</name> <value>/home/hadoop-2.6.5/tmp</value> //tmp目录自己创建的 </property> </configuration>
之后到mapred-site.xml,这时候我们发现etc目录下是没有mapred-site.xml文件的,但是有一个mapred-site.xml.template,这时候我们将其复制改一下名字就可以了
cp mapred-site.xml.template mapred-site.xml vim mapred-site.xml <configuration> <!--配置MR的运行框架为Yarn--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
然后是yarn-site.xml
vim yarn-site.xml <configuration> <!-- Site specific YARN configuration properties --> <!--配置主节点ResourceManager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>localhost</value> //本机ip </property> <!--配置NodeManager的执行方式--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
到这里所有的配置就完成了
接下来初始化主节点NameNode
hdfs namenode -format
之后进入sbin目录下,启动hadoop
start-all.sh
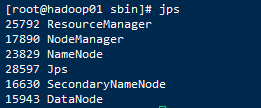
因为之前单机版设置过免密,所以这里不用再输入多次密码了,启动完成后jps查看
 最简单的查看方法可以使用ls -ll、ls-lh命令进行查看,当使用...
最简单的查看方法可以使用ls -ll、ls-lh命令进行查看,当使用...