词的向量化就是将自然语言中的词语映射成是一个实数向量,用于对自然语言建模,比如进行情感分析、语义分析等自然语言处理任务。下面介绍比较主流的两种词语向量化的方式:
第一种即One-Hot编码,,是一种基于词袋(bag of words)的编码方式。假设词典的长度为 N 即包含 N 个词语,并按照顺序依次排列。One-Hot 编码将词语表示成长度为 N 的向量,每一向量分量代表词典中的一个词语,则 One-Hot 编码的词语向量只有一位分量值为 1。假设词语在词典中的位置为 k,那么该词语基于 One-Hot 编码的词语向量可表示为第 k 位值为 1,其他位全为 0 的向量。这种方式很容易理解,比如:
假设我们有词典{今天,我,不想,去,上课,因为,我,是,小宝宝},那么句子“今天我不想去上课”就可以表示为”[1,1,0],“因为我是小宝宝”就可以表示为[0,1]。这种编码方式简单明了。但是也具有明显的问题:
- 未能考虑词语之间的位置顺序关系;
- 无法表达词语所包含的语义信息;
- 无法有效地度量两个词语之间的相似度;
- 具有维度灾难。
首先,我们最后得到的向量只能表示每个词语的存在关系,比如[1,0]不仅可以表示“今天我不想去上课”,还可以表示“我不想今天去上课”,这种词语位置顺序的差别有时带来的灾难是巨大了,甚至会出现“我是你爸爸”和“你是我爸爸”傻傻分不清楚的现象;此外,我们这个粗糙的模型将每个词语都看成是对等的位置,主谓宾定状补完全分不开,语义信息完全被掩藏了;当词典过大时也会带来纬度灾难,我们可能用到的词语或许成千上万个,我们采用成千上万维度的向量来表示一个简简单单的句子显然是不明智的。
第二种是word2vec。该模型是以无监督方式从海量文本语料中学习富含语义信息的低维词向量的语言模型,word2vec 词向量模型将单词从原先所属的空间映射到新的低维空间,使得语义上相似的单词在该空间内距离相近,word2vec 词向量可以用于词语之间相似性度量,由于语义相近的词语在向量山空间上的分布比较接近,可以通过计算词向量间的空间距离来表示词语间的语义相似度,因此 word2vec 词向量具有很好的语义特性。word2vec 模型是神经网络在自然语言处理领域应用的结果,它是利用深度学习方法来获取词语的分布表示,可以用于文本分类、情感计算、词典构建等自然语言处理任务。
简单的举个例子,“老师”之于“学生”类似于“师父”之于“徒弟”,“老婆”之于“丈夫”类似于“女人”之于“男人”。
word2vec 包含两种训练模型,分别是连续词袋模型 CBOW 和 Skip-gram 模型。其中CBOW 模型是在已知词语 W(t)上下文 2n 个词语的基础上预测当前词 W(t);而 Skip-gram模型是根据词语 W(t)预测上下文 2n 个词语。假设 n=2,则两种训练模型的体系结构如图所示,Skip-gram 模型和连续词袋模型 CBOW 都包含输入层、投影层、输出层。
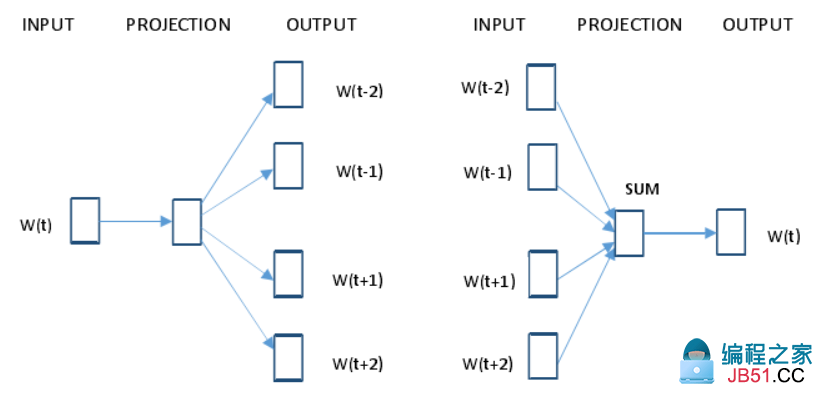
(左边为Skip-gram模型,右边为CBOW模型)
假设语料库中有这样一句话"The cat jumped over the puddle",以 Skip-gram模型为例,它是要根据给定词语预测上下文。如果给定单词"jumped"时,Skip-gram 模型要做的就是推出它周围的词:"The", "cat", "over", "the", "puddle",如图所示。

要实现这样的目标就要让如公式1的条件概率值达到最大,也即在给定单词 W(t) 的前提下,使单词 W(t)周围窗口长度为 2n 内的上下文的概率值达到最大。为了简化计算,将公式1转化为公式2,即求公式2的最小值。
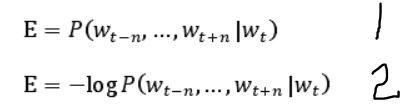
CBOW 模型和上面差不多,仅仅是将条件概率的前后两项颠倒了个,它是要根据上下文预测目标词语出现的概率。如给定上下文"The", "cat", "over", "the", "puddle",CBOW 模型的目标是预测词语"jumped"出现的概率,如图所示:

要实现这样的目标就要让如公式3的条件概率值达到最大,即在给定单词 W(t)上下文 2n 个词语的前提下,使单词 W(t)出现的概率值达到最大,同样为了简化计算,将公式3转化为公式4,即求公式4的最小值。
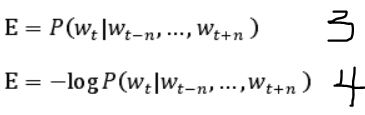
我们接下来会在pycharm中演示word2vec,这里首先要选取语料库,我从网上下载了一份三国演义的原文,并进行了中文分词处理,采用的是jieba库。
1 import jieba.analyse 2 codecs 3 4 f=codecs.open('F:/nlp/SanGuoYanYi.txt','r',encoding="utf8") 5 target = codecs.open("F:/nlp/gushi.txt",'w',1)"> 6 7 print('open files' 8 line_num=1 9 line = f.readline() 10 11 #循环遍历每一行,并对这一行进行分词操作 12 #如果下一行没有内容的话,就会readline会返回-1,则while -1就会跳出循环 13 while line: 14 print('---- processing ',line_num,' article----------------'15 line_seg = " ".join(jieba.cut(line)) 16 target.writelines(line_seg) 17 line_num = line_num + 1 18 line =19 20 #关闭两个文件流,并退出程序 21 f.close() 22 target.close() 23 exit()
我们在上面的代码中进行了分词处理,得到类似下面的txt文档:
滚滚 长江 东 逝水 , 浪花 淘尽 英雄 。 是非成败 转头 空 。 青山 依旧 在 , 几度 夕阳红 。 白发 渔樵 江渚上 , 惯看 秋月春风 。 一壶 浊酒 喜相逢 。 古今 多少 事 , 都 付笑谈 中 。
— — 调寄 《 临江仙 》
话 说 天下 大势 , 分久必合 , 合久必分 。 周末 七 国 分争 , 并入 于 秦 。 及 秦灭 之后 , 楚 、 汉 分争 , 又 并入 于汉 。 汉朝 自 高祖 斩 白蛇 而 起义 , 一统天下 , 后来 光武 中兴 , 传至 献帝 , 遂 分为 三国 。 推其致 乱 之 由 , 殆 始于 桓 、 灵 二帝 。 桓帝 禁锢 善类 , 崇信 宦官 。 及桓帝 崩 , 灵帝 即位 , 大将军 窦武 、 太傅陈 蕃 , 共 相 辅佐 。 时有 宦官 曹节 等 弄权 , 窦武 、 陈蕃 谋 诛 之 , 机事不密 , 反为 所害 , 中 涓 自此 愈横 。
建宁 二年 四月 望 日 , 帝御 温德殿 。 方 升座 , 殿角 狂风 骤起 。 只见 一条 大 青蛇 , 从 梁上 飞 将 下来 , 蟠于 椅上 。 帝惊 倒 , 左右 急救 入宫 , 百官 俱奔避 。 须臾 , 蛇 不见 了 。 忽然 大雷 大雨 , 加以 冰雹 , 落到 半夜 方止 , 坏 却 房屋 无数 。 建宁 四年 二月 , 洛阳 地震 ; 又 海水 泛溢 , 沿海居民 , 尽 被 大浪 卷入 海 中 。 光 和 元年 , 雌鸡化雄 。 六月 朔 , 黑 气 十余丈 , 飞入 温雄殿 中 。 秋 七月 , 有虹 现于 玉堂 ; 五原 山岸 , 尽 皆 崩裂 。 种种 不祥 , 非止 一端 。 帝下 诏 问 群臣 以 灾异 之 由 , 议 郎蔡邕 上 疏 , 以为 霓 堕 鸡化 , 乃妇 寺 干政之 所致 , 言 颇 切直 。 帝览奏 叹息 , 因起 更衣 。 曹节 在 后 窃视 , 悉 宣告 左右 ; 遂 以 他 事 陷邕 于 罪 , 放归 田里 。 后张 让 、 赵忠 、 封谞 、 段 珪 、 曹节 、 侯览 、 蹇 硕 、 程旷 、 夏恽 、 郭胜十人 朋比为奸 , 号 为 “ 十常侍 ” 。 帝尊 信张 让 , 呼为 “ 阿父 ” 。 朝政 日非 , 以致 天下人 心思 乱 , 盗贼 蜂起 。
时 巨鹿郡 有 兄弟 三人 , 一名 张角 , 一名 张宝 , 一名 张梁 。 那 张角本 是 个 不 第 秀才 , 因入 山 采药 , 遇一 老人 , 碧眼 童颜 , 手执 藜 杖 , 唤角 至 一洞 中 , 以 天书 三卷 授 之 , 曰 : “ 此名 《 太平 要术 》 , 汝得 之 , 当代 天 宣化 , 普 救世 人 ; 若萌 异心 , 必获 恶报 。 ” 角拜 问 姓名 。 老人 曰 : “ 吾 乃 南华 老仙 也 。 ” 言 讫 , 化阵 清风 而 去 。 角得 此书 , 晓夜 攻习 , 能 呼风唤雨 , 号 为 “ 太平 道人 ” 。 中平 元年 正月 内 , 疫气 流行 , 张角 散施 符水 , 为 人 治病 , 自称 “ 大 贤良 师 ” 。 角有 徒弟 五百余 人 , 云游四方 , 皆 能书符 念咒 。 次后 徒众 日多 , 角乃立 三十六方 , 大方 万余 人 , 小 方 六七千 , 各 立渠帅 , 称为 将军 ; 讹言 : “ 苍天 已死 , 黄天 当立 ; 岁 在 甲子 , 天下 大吉 。 ” 令人 各以 白土 , 书 “ 甲子 ” 二字于 家中 大门 上 。 青 、 幽 、 徐 、 冀 、 荆 、 扬 、 兖 、 豫八州 之 人 , 家家 侍奉 大 贤良 师 张角 名字 。 角遣 其党 马元义 , 暗 赍 金帛 , 结交 中 涓 封谞 , 以为 内应 。 角 与 二弟 商议 曰 : “ 至 难得 者 , 民心 也 。 今 民心 已顺 , 若 不 乘势 取 天下 , 诚为 可惜 。 ” 遂 一面 私造 黄旗 , 约期 举 事 ; 一面 使 弟子 唐周 , 驰 书报 封谞 。 唐周 乃径 赴 省 中 告变 。 帝召 大将军 何进 调兵 擒 马元义 , 斩 之 ; 次收 封谞 等 一干人 下狱 。 张角 闻知 事露 , 星夜 举兵 , 自称 “ 天公 将军 ” , 张宝称 “ 地公 将军 ” , 张梁 称 “ 人公 将军 ” 。 申言 于众 曰 : “ 今汉运 将 终 , 大圣 人出 。 汝 等 皆宜 顺天 从 正 , 以乐 太平 。 ” 四方 百姓 , 裹 黄巾 从 张角 反者 四五十万 。 贼势 浩大 , 官军 望风而靡 。 何进 奏帝 火速 降 诏 , 令 各处 备御 , 讨贼 立功 。 一面 遣 中郎将 卢植 、 皇甫嵩 、 朱俊 , 各引 精兵 、 分 三路 讨之 。
且说 张角 一军 , 前犯 幽州 界分 。 幽州 太守 刘焉 , 乃 江夏 竟陵 人氏 , 汉鲁恭 王 之后 也 。 当时 闻得 贼兵 将 至 , 召 校尉 邹靖 计议 。 靖 曰 : “ 贼兵 众 , 我兵 寡 , 明公宜 作速 招军 应敌 。 ” 刘焉然 其 说 , 随即 出榜 招募 义兵 。
榜文 行到 涿县 , 引出 涿县 中 一个 英雄 。 那人 不 甚 好 读书 ; 性 宽 和
基于上面已经处理好的文档,我们进行word2vec的词向量训练:
# -*- coding: utf-8 -*- from gensim.models Word2Vec from gensim.models.word2vec LineSentence logging logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s',level=logging.INFO) # Word2Vec第一个参数代表要训练的语料 # sg=1 表示使用Skip-Gram模型进行训练 # size 表示特征向量的维度,默认为100。大的size需要更多的训练数据,但是效果会更好. 推荐值为几十到几百。 # window 表示当前词与预测词在一个句子中的最大距离是多少 # min_count 可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉,默认值为5 # workers 表示训练的并行数 #sample: 高频词汇的随机降采样的配置阈值,默认为1e-3,范围是(0,1e-5) def A(): #首先打开需要训练的文本 shuju = open('F:/nlp/gushi.txt','rb') #通过Word2vec进行训练 model = Word2Vec(LineSentence(shuju),sg=1,size=100,window=10,min_count=5,workers=15,sample=1e-3) #保存训练好的模型 model.save('F:/nlp/SanGuoYanYiTest.word2vec') print('训练完成') if __name__ == '__main__': A()
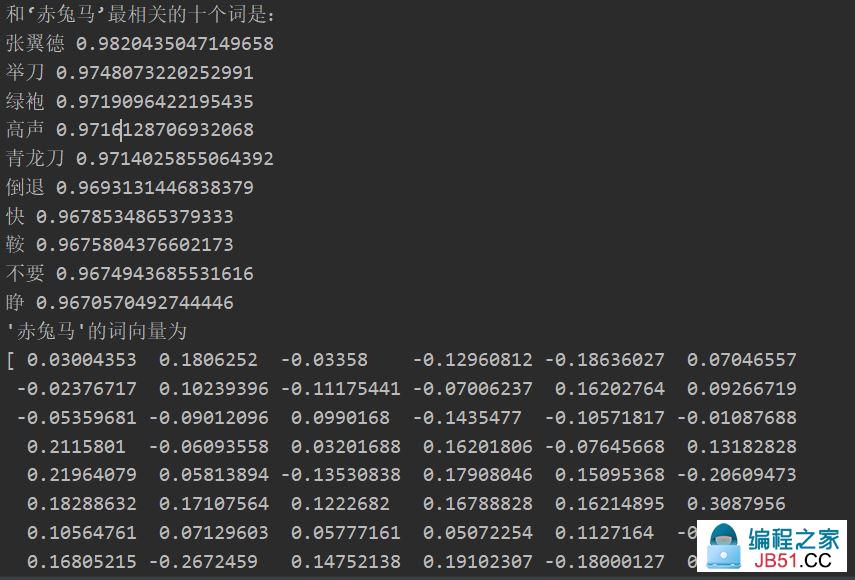
显示“训练完成”后我们就得到了一个完好的模型,输出和“赤兔马”最相关的词语,以及其词向量,测试结果如下:
 文章浏览阅读5.3k次,点赞10次,收藏39次。本章详细写了mysq...
文章浏览阅读5.3k次,点赞10次,收藏39次。本章详细写了mysq... 文章浏览阅读1.8k次,点赞50次,收藏31次。本篇文章讲解Spar...
文章浏览阅读1.8k次,点赞50次,收藏31次。本篇文章讲解Spar... 文章浏览阅读928次,点赞27次,收藏18次。
文章浏览阅读928次,点赞27次,收藏18次。 文章浏览阅读1.1k次,点赞24次,收藏24次。作用描述分布式协...
文章浏览阅读1.1k次,点赞24次,收藏24次。作用描述分布式协... 文章浏览阅读1.5k次,点赞26次,收藏29次。为贯彻执行集团数...
文章浏览阅读1.5k次,点赞26次,收藏29次。为贯彻执行集团数...