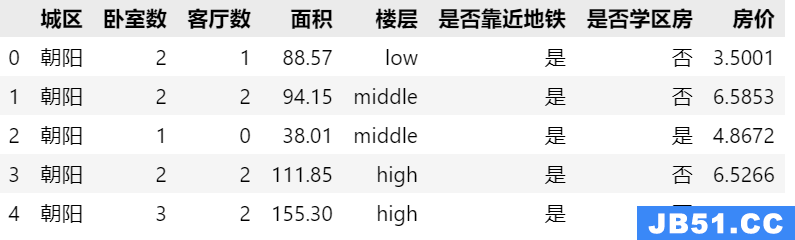
基于内容的变长分块(CDC)技术,可以用来对文件进行变长分块,而后用来进行重复性检测,广泛用于去重系统中。后来又出现了对相似数据块进行delta压缩,进一步节省存储开销。所以就需要一种高效的相似性检测算法,在论文 WAN Optimized Replication of Backup Datasets Using Stream-Informed Delta Compression 提出的super-features 算法具有很好的效果。主要思想是在滑动窗口进行分块的过程中,通过一个窗口的rabin fingerprint 我们可以随机的得到一个数值,如果它比这个块中所有窗口w的rabin指纹都大,就把它记为一个特征值 feature-i,通过这样的方法得到的多个feature,计算rabin 指纹得到的就是超级特征值SF,下图每个SF有四个特征值得到。

F1,F2,F3 分别在F的基础上头,尾,中间加入额外字节,发现得到的两个超级特征值都一样 Supfeature[0]=5465959093573163876,Supfeature[1]=7673021043978770954。
参考: