文本挖掘的定义
文本挖掘即文本数据库中的知识发现,是从大量文本的集合或语料库中发现隐含的、有潜在使用价值的模式和知识。
情感分析,通过处理能表达情感倾向的词语特征向量,得到每个文本的情感倾向及程度。
文本挖掘的流程

文本语料的采集
文本采集主要是利用搜索引擎或者网络爬虫技术,将所需的网页信息抓取过来。
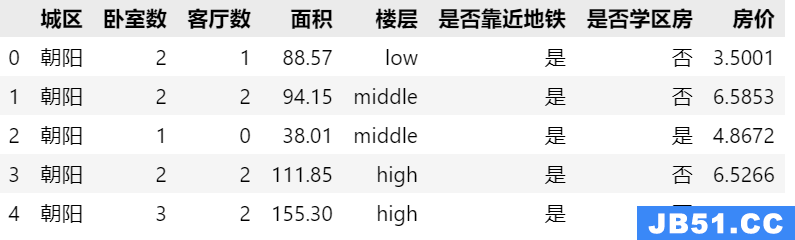
火车采集器采集电商网站的评论信息。
文本预处理

分词
停用词过滤
就被称为停用词。
特征提取,权值转换,构建矩阵文本
如果将分词之后的所存词都作为特征项,会引起维数灾难,而且会影响后续研究的准确性。因为分词后得到的是一个极其稀疏的矩阵,所以需要通过特征提取将信息量小的,不重要的词汇从特征空间中去掉,提取出有代表性的,重要的词汇,以 降低矩阵的维度。
文本的权值转换及向量表示
为了构建文本向量,需要为文本(特征提取后)中的词语设定权值
常见方法:布尔型处理、文档频率、信息增益、卡方检验、TF-IDF等
TF-IDF
见《基于Web文本挖掘的企业口碑情感分类模型研究》P46
文本挖掘及质量评估基于词典、KNN、神经网络、SVM等等
评估方法:查准率、查全率
应用
– 类别 {spam,not-spam}
新闻出版按照栏目分类
– 类别 {政治,体育,军事,…}
词性标注
– 类别 {名词,动词,形容词,新宋体; font-size:14px; line-height:25.1875px">
词义排歧
– 类别 {词义1,词义2,新宋体; font-size:14px; line-height:25.1875px">
计算机论文的领域
– 类别ACM system
H.3: information retrieval and storage
视频文件下载地址: