摘自:毕马威大数据挖掘
微信号:kpmgbigdata
刚刚过去的双11、双12网络购物节中,无数网友在各个电商网站的促销大旗下开启了买买买模式。不过,当你在网上选购商品时,同类的商品成千上万,哪些因素会影响你选购某件商品呢?商品评论一定是一个重要的参考吧。一般我们总会看看历史销量高不高,用户评论好不好,然后再去下单。
然而各位一定也有所耳闻,买的不如卖的精,刷单的、刷评论的始终横行网上,没准你看到的评论就是卖家自己刷出来的。事实上,许多精明的淘宝卖家会在双十一等网购高峰期售卖“爆款”,“干一票就撤”,这正是虚假评论的温床。有时我们选购商品,经常会发现许多条看起来十分夸张的评论,如某女鞋的商品评论:
“超级好看的鞋,随便搭配衣服就觉得自己像女神,又不磨脚,站一天都不会累。下次还来买,赶快上新款哦!”
“有史以来最满意的鞋,妈妈看了说是真皮的,卖家态度又很好,发货超快,诚信卖家,特别满意的一次购物!”

连续几百几千条“真情实感”的好评这样刷下来,恐怕会有许多顾客被洗脑:这个商品销量真高,评论也不错,那就买这家吧!结果网上的爆款买回家却变成了废品。我们买家真是绝对的信息弱势方,卖家给出的描述真假尚且不知,刷好评又让人防不胜防。那么,如何才能识别刷单评论呢?我们在此介绍一种借助文本挖掘模型的破解之道。
首先要解决数据来源问题,可以从网站上批量下载这些评论,也就是爬虫。目前有两种方法,一种是编程,可以使用python、java等编程语言去编写爬虫程序;还有一种是使用成熟爬虫软件,可以利用界面操作来爬虫。笔者决定使用免费的gooseeker软件来做,这个软件是Firefox浏览器的插件,避免了很多网站动态渲染不好分析的问题,它借助了浏览器的功能,只要在浏览器上看到的元素就可以方便地下载。该软件提供了详细的教程和用户社区,可以指导用户一步步设置抓取内容、抓取路线、连续动作、同类型网页的重复抓取,大家可以自行学习使用。
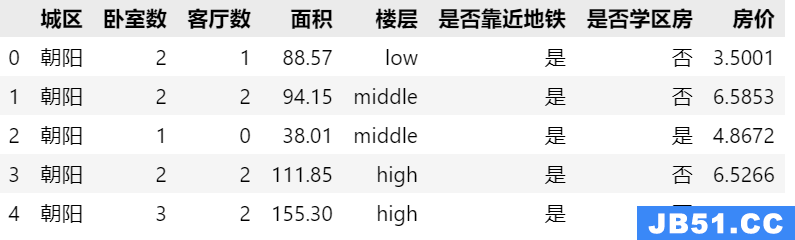
笔者最终抓取了四款同类型的鞋子的评论数据,包括会员名、商品描述、购买日期、购买型号、评论日期、评论文本等,共计5000多条数据。我们特意选取了具有刷单倾向的商品,可以看出,其中许多评论日期连续、会员名相似、买家等级较低;经过人眼识别,刷单评论占比约30%。我们意在使用这些数据去构建刷单评论识别模型,然后可以用这里得出来的规则去识别其它鞋类商品的刷单评论。
SASEnterprise miner 13.2是一款大家熟知的数据挖掘工具,它可以针对大型数据进行分析,并根据分析结果建立精确的预测和描述模型,因此为我们所选用,不过使用其他软件也是相同的分析思路。
我们把先前获取的5000条评论一分为二,其中70%作为训练样本,30%作为验证样本。首先,用文本解析将训练样本中的评论文本内容拆词,在拆词时可以选择忽略缺乏实际意义的代词、感叹词、介词、连词,忽略数字与标点符号。以上拆词过程相当于把非结构化数据转成了结构化数据,以前的一段文本如今可以用若干列来表示,每列代表一个词,如果文本中出现了该词该列取值为1,否则取值为0。

现在我们还不能直接拿它来建模,通过上图我们可以发现很多词只出现在少部分文章中,可以使用文本过滤器节点来去除词频很低的词。
在文本过滤器中可以设置最小文档数,指定排除小于该文档出现数目的词条,同时也要排除像“就”、“这”、“是”、“有”这样词频高却意义不大的词。除此之外,还可以进行同义词处理,我们可以手动添加同义词,也可以导入外部的同义词库。比如,“暖和”与“保暖”是同义词,“好看”与“漂亮”可以互相替代……
接下来,我们可以使用文本规则生成器节点来建模,发现哪些词组组合与刷单有直接的关系:
我们将训练样本中的真实评论设置为0(蓝色),刷单虚假好评设置为1(红色)。上图中可以看出,提到“暖和”(包括同义词“保暖”)这样的词时,评论极可能是真实的;而写着“鞋子很时尚哦”“做工精细,还会再买”而没有提到暖和与否的,则多半是虚假好评。
说到这里,你可能会好奇:为什么“暖和”这样一个普通的词,倒成了真假评论的试金石?
我们不妨回想一下自己作为普通买家的购物经历:在收到货品并试用之后,通常只会简单描述一下自己的使用感受,这些感受一定。而水军则不然,他们从来没有真正收到商品,更谈不上试穿啦,为了完成业务指标,只好按照卖家提供的商品描述,尽量从质量、物流、服务态度甚至搭配等多方面强调商品本身的特性。从我们所做的案例来讲,“暖和”自然属于亲身感受,而“真皮”“做工”之类,恐怕不是普通买家最想反馈的性质。
那么这个模型的总体效果如何呢?我们可以用累积提升度这个指标来评价:
我们还留下了30%的验证样本,现在它们可以现身来验证成果了。请看上图中的粉红色曲线:如果用这个模型去对评论进行打分,按照疑似为虚假评论(“1”)的概率去排名,取前5%的评论时,提升度为3倍;我们已知虚假评论约占总体的30%,也就是说,概率排名前5%的评论中有九成都是刷的,从而证明我们的模型相当精准地捕捉了刷单评论。
最后,我们要为卖家说句公道话:淘宝刷单恶性竞争严重,完全不刷好评的店家恐怕不多,不能说有刷评论的店就完全不能下手,90%刷单的商品实在骇人听闻,10%刷单的店则或许质量尚可接受。这也进一步说明了我们的模型的作用:判断商品的刷单比例,比逐条判断评论是否虚假更加实用。
如今网络水军也在持续进化中,写出的评论越来越真情实感、具有极强的误导性,单凭肉眼分辨既浪费时间、又易被迷惑;但虚假评论可以推陈出新,我们的模型更可以随时跟进“学习”。如果将本文中的方法进行推广,则可以形成一个捕捉评论——文本解析——建立模型——判断虚假评论比例的标准过程,这样的方法无疑相当具有实用性。

【限时干货下载】

点击下图,阅读“2016大数据发展7大趋势”

2016/1/31前
2015年12月干货文件打包下载,请点击大数据文摘底部菜单:下载等--12月下载
大数据文摘精彩文章:
可视化】感受技术与艺术的完美结合
安全】 关于泄密、黑客、攻防的新鲜案例
算法】 既涨知识又有趣的人和事
谷歌】 看其在大数据领域的举措
院士】 看众多院士如何讲大数据
隐私】 看看在大数据时代还有多少隐私
医疗】 查看医疗领域文章6篇
征信】 大数据征信专题四篇
大国】 “大数据国家档案”之美国等12国
体育】 大数据在网球、NBA等应用案例
回复【志愿者】了解如何加入大数据文摘
长按指纹,即可关注“大数据文摘”

专注大数据,每日有分享