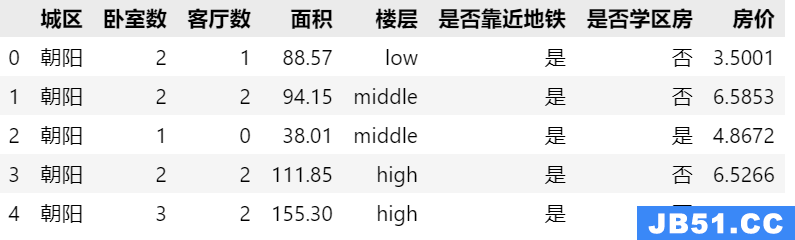
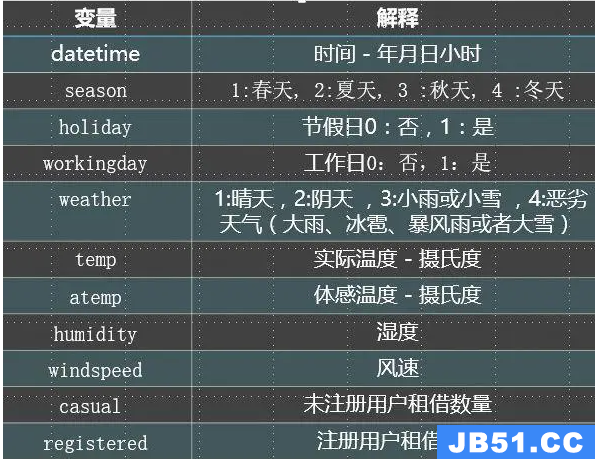
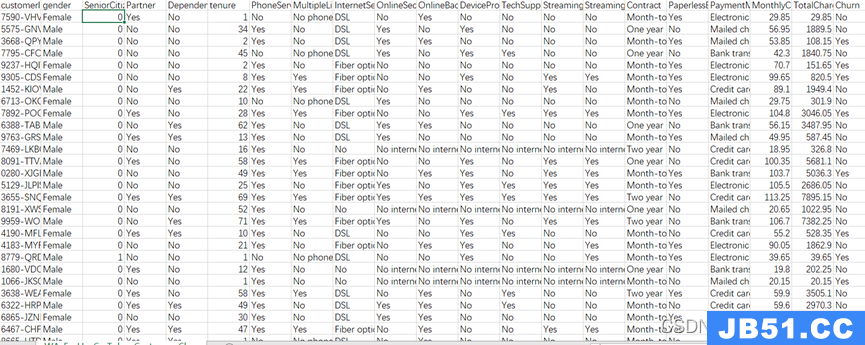
在只有【论文标题、发布时间、作者、会议名称】这四种信息的情况下,首先提取出所有这四种信息:
代码产生的结果如下,数据结构类似于headerTable,看结果就知道了,不再介绍:
authorDict={} #{authorName: total(frequence,startYear,endYear),{eachConf(frequence,endYear)}}
authorDict,conferenceDict=CountAuthorAndConferenceFrequence(tranDB)
print len(authorDict) #31886
print authorDict["Ying Wu"]
#[51,2000,2015,{'KDD': [1,2007,2007],'SDM': [1,2005,2005],'CVPR': [49,2015]}]
print conferenceDict
#{'CVPR': 7722,'PAKDD': 1760,'ICML': 1111,'KDD': 2360,'COLT': 736,'ICDM': 3873,'DMKD': 47,'SIGIR': 2772,'ECML/PKDD': 1036,'SDM': 1156,'WSDM': 618,'NIPS': 3852}
代码为:
def CountAuthorAndConferenceFrequence(tranDB):
authorDict={} #{authorName: total(frequence,endYear)}}
conferenceDict={} #{conference: count}
for i,(conf,year,authorList) in enumerate(tranDB):
print "trans",i,"=="*20
if conf is np.nan or year is np.nan or authorList is np.nan:
continue #for tranDB[2426,:]
if conferenceDict.has_key(conf):
conferenceDict[conf]+=1
else:
conferenceDict[conf]=1
for author in authorList.split("|"):
if authorDict.has_key(author):
#total(frequence,endYear)
authorDict[author][0]+=1
if year<authorDict[author][1]:
authorDict[author][1]=year
elif year>authorDict[author][2]:
authorDict[author][2]=year
#eachConf(frequence,endYear)
if authorDict[author][3].has_key(conf):
authorDict[author][3][conf][0]+=1
if year<authorDict[author][3][conf][1]:
authorDict[author][3][conf][1]=year
elif year>authorDict[author][3][conf][2]:
authorDict[author][3][conf][2]=year
else:
authorDict[author][3][conf]=[1,year]
else:
authorDict[author]=[1,{}]
authorDict[author][3][conf]=[1,year]
return authorDict,conferenceDict
提取核心研究者,就是阈值控制,没技术含量:
'''
authorDict={} #{authorName: total(frequence,endYear)}}
conferenceDict={} #{conference: count}
'''
def FindCoreResearcher(authorDict,conferenceDict,coreSupport=0.05):
wf=open("CoreResearcher.txt","w")
allConferencetotalCount=0
for conf,count in conferenceDict.items():
allConferencetotalCount+=count
coreSup=count*coreSupport
if coreSup<2: #at least 2,or how can we say you are a core researcher?
coreSup=2
elif coreSup>20: #some conference find to few core researchers
coreSup=coreSup/2
elif coreSup>10: #some conference find to few core researchers
coreSup=10 #but is we choose coreSup/2,will to many,so we select this threshold
print "conf:",conf,",total paper count:",count,"##"*20,"coreSup=",coreSup
wf.write("conf:"+conf+",total paper count:"+str(count)+"##"*20+"coreSup="+str(coreSup)+"\n")
for author in authorDict.keys():
if authorDict[author][3].has_key(conf) and authorDict[author][3][conf][0]>=coreSup:
print "%s is a core researcher with support %s" % (author,authorDict[author][3][conf][0])
wf.write(author+" is a core researcher with support "+str(authorDict[author][3][conf][0])+"\n")
wf.write("\t His/Her active time is==>["+str(authorDict[author][3][conf][1])+"-"+str(authorDict[author][3][conf][2])+"]\n")
paperCount_authorCount_Dict={}
coreSup=allConferencetotalCount*coreSupport
if coreSup>len(conferenceDict)*15:
coreSup=len(conferenceDict)*15/4 #at least a paper one year in (at least 1/4 of all the conferences)
print "all conference,allConferencetotalCount,"the overall coreSupport=",coreSup
wf.write("all conference,total paper count:"+str(allConferencetotalCount)+"##"*20+"the overall coreSupport="+str(coreSup)+"\n")
for author in authorDict.keys():
if authorDict[author][0]>=coreSup:
print "%s is a core researcher with support %s" % (author,authorDict[author][0])
wf.write(author+" is a core researcher with support "+str(authorDict[author][0])+"\n")
wf.write("\t His/Her active time is==>["+str(authorDict[author][1])+"-"+str(authorDict[author][2])+"]\n")
#count how many authors have published "authorDict[author][0]" papers
#this is for the frequent pattern minSupport
if paperCount_authorCount_Dict.has_key(authorDict[author][0]):
paperCount_authorCount_Dict[authorDict[author][0]]+=1
else:
paperCount_authorCount_Dict[authorDict[author][0]]=1
wf.close()
return paperCount_authorCount_Dict