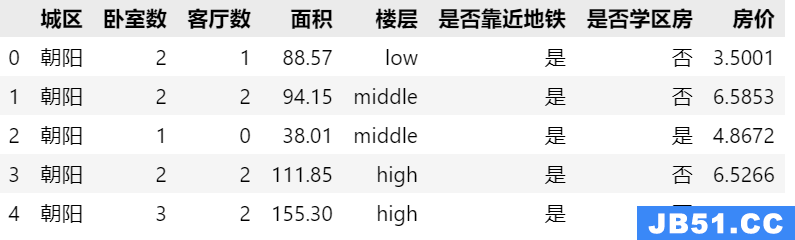
最近做数据挖掘,发现rapidminer是一款数据清洗、处理和转换的好工具,尤其在数据量不大的情况下。和R语言相比,rapidminer在数据处理方面要简单直观得多。虽然rapidminer的功能可能不如R强大。另外,我们也可以在rapidminer中可以直接利用Java/Groovy来编写程序,对数据进行处理和转换。
现在以 rapidminer6.0为例,来说明一下如何写一段小程序,去掉那些数据缺失量大于80%的变量。因为数据缺失量超过80%,我们很难补全它们。
我们可以打开rapidminer中的Execute Script算子并点击Edit Text属性输入下列Java程序段:
/**
* Carl Wu 吴文旷
* The code will remove these attributes whose missing values are more than 80% of
* the total examples
*
*/
ExampleSet exampleSet = operator.getInput(ExampleSet.class);
Attributes attributes = exampleSet.getAttributes();
List cols_with_missing_values = new ArrayList();
//循环所有列
for (Attribute attribute : exampleSet.getAttributes()) {
String name = attribute.getName();
Attribute sourceAttribute = attributes.get(name);
int totalRecords=0;
int missingRecords=0;
//循序一个变量的所有行,统计缺失值的数量
for (Example example : exampleSet) {
totalRecords=totalRecords+1;
if(example[name]==null || example[name].equals("?")){
missingRecords=missingRecords+1;
}
}
//如果缺失数据量超过80%,将该变量名保存到LIst中
if(missingRecords*1.0/totalRecords>=0.8){
cols_with_missing_values.add(sourceAttribute);
}
}
//从原数据集中移除数据大量缺失的列
for(Attribute name:cols_with_missing_values){
attributes.remove(name);
}
return exampleSet;
这段小程序的运行效果如下图所示。在没有处理之前,我们一共有90个样本,536个属性字段:

运行小程序处理后,数据字段数减少到234个,缺失值较多的字段都被移除了。

当然,我们也可以用几乎无所不能的数据分析工具R语言来完成这项任务。具体代码如下:
##### 该函数将移除原始数据(odf)中数据缺失量大于给定比例(missingPercent)的列 ##### Author: Carl Wu(吴文旷) removeMissingCols <- function (odf,missingPercent){ cols <- ncol(odf) rows <- nrow(odf) newMaxtrix <- NULL names_new <- NULL noMissVals <- 0 for(col in 1:cols){ noMissVals <- 0 for(row in 1:rows){ if(!is.na(odf[row,col])){ noMissVals <- noMissVals +1 } } #如果这一列缺失值的比例小于给定的比例,则留下该列 if((rows-noMissVals)/rows <= missingPercent){ newMaxtrix <- cbind(newMaxtrix,odf[,col]) names_new <- c(names_new,names(odf)[col]) } } new_data <- as.data.frame(newMaxtrix) names(new_data) <- names_new new_data }
另外,在R语言的DMwR包中有一个函数叫manyNAs,可以移除缺失值大于一定比例的样本。注意这里是样本,而不是数据列。示例代码如下:
#读取原始数据
data_original <- read.table("original_data.csv",header = TRUE,sep = ",")
#下面代码打印出原始数据有123行,41个变量
dim(data_original)
#加载DMwR
library(DMwR)
#列出所有缺失值大于40%(0.4)的样本号
manyNAs(data_original,0.4)
#去掉缺失值大于40%(0.4)的样本,将新的数据训练集赋值到一个新的数据框new_data中
new_data <- data_original[-manyNAs(data_original,0.4),]
#下面代码打印出新数据的维数,新的数据有112行,41个变量。原始数据中的12个样本由于缺失值大于40%而被移除。
dim(new_data)