1. cloudera官网 http://www.cloudera.com/ 2. cloudera文档 http://www.cloudera.com/documentation.html 3. 文档分为三个部分 3.1 cloudera enterprise: cdh,cloudera manger,search,impala,spark。 3.2 cloudera director: 安装指南,配置,以及使用cloudera director 3.3 apache kafka: 安装,管理,使用 4. cloudera enterprise文档 4.1 选择版本5.7,它对应的所有文档都在 http://www.cloudera.com/documentation/enterprise/5-7-x/topics/cdh_intro.html 4.2 下文都是按照这个文档的大小类撰写。 ----------------------------------------------------- 1. cloudera introduction 1.1 cdh overview 1.1.1 cdh就是好啦就是好。一张架构图http://www.cloudera.com/documentation/enterprise/5-7-x/images/xcdh.png.pagespeed.ic.iqEqmMFnIn.png。 1.1.2 impala overview:为hdfs,hbase,s3提供快速交互式的sql查询。impala和hive使用相同的metadata,近似的语法,支持odbc,都可以以hue为用户界面。 impala的结构一张图http://www.cloudera.com/documentation/enterprise/5-7-x/images/impala_arch.jpeg。client: hue,odbc,jdbc,impala shell; hive metastore: 元数据; impala--进程,运行在每个datanode节点,提供query处理; hbase和hdfs:存储数据。 impala的sql支持sql92。 imapa的安全:kerberos。 1.1.3 cloudera search overview 提供近实时的检索,检索存储在hdfs和hbase的数据。近实时索引,批量索引,全文检索,钻取导航,并提供各种接口。 基于apache solr,包括lucene,solrcloud,apache tika,solr cell。 索引创建在hdfs上; 用mapred创建批量索引; 近实时索引:事件从flume进入存储写入hdfs,事件会被直接写入到索引。 集成Apache tika从各种文件类型html,doc,pdf,json,xml,avro,hadoop sequence,snappy里取出结构化数据和元数据。 Lily HBase Indexer Service:能对hbase进行建立索引和搜索。 clouder search 架构:分布式的,检索内容被分拆成小份多副本存储在多个服务器; 需要zookeeper,hdfs,solr安装; client以http提交查询,namenode将response发给datanode, datanode将request发给临近的主机做查询,查询结果汇集后发给client; 1.1.4 Apache Sentry Overview: 可插入式、精确控制细节、基于角色的安全控制,管理 hive,hive metastore,hcatalog,solr,hdfs。 1.1.5 Apache Spark Overview: 高性能计算框架,批量和交互式计算。sql, streaming,mllib, graphx。 1.1.5 文件格式和压缩:cdh支持hadoop所有文件格式; avro和parquet。 1.1.6 外部文档:这里列出了非常多的hadooop生态的开源软件。 1.2 cludera manager 5 overview 1.2.1 overview web界面,管理整个cdh技术栈。 一个cloudera manager可以管理多个cdh集群,但一个cdh集群只能被一个cloudera manager管理。一个cloudera manager,是一个逻辑整体,它包括一组主机host,一个指定的chd版本,以及相应的服务实例和角色实例。 host:一个物理机或者虚拟机,上面运行角色实例。 rack: 机架,管理多个物理机。 service: 一个服务功能,比如mapreduce,yarn,spark,accumulo等等。 servrice insatance: 运行service的instance,比如yarn和hdfs-1。 role: 比如说,hdfs是一个service,而namenode,secondary namenode,datanode,balace等等就是role。 role instance: 运行role的实例,比如说,datanode-h1,namenode-h1等等。 role group: 一组role instances的配置数据。 host template: 一组role grops。当一个template应用到一个host,那么就创建了每一个role group的一个role instance,且被关联到这个host。 gratway: 如果一个host上的role需要一个服务,但这个服务在这个host上没有,那么,这个role就需要一个连接到它需要的role的client配置。 parcel: 一个二进制发行格式包括编译后代码,meta信息比如包描述,包版本,依赖项等等。 static service pool:静态资源,比如cpu,内存, io等等。 架构:核心是cloudera manager server,它上面有admin console web server和应用逻辑,安装软件,配置,启动和停止服务,管理整个集群; 每个host上有个一个agent负责起停进程诸多管理; databaase负责存储; managerment service管控诸多roles; cloudera repository存放要安装的软件; clinent有两种,admin console和api。 agent每15秒发心跳给cloudera manger server。 State Management:model态是静态的,runtime是动态的,修改了前者要重启后者。 Configuration Management:cloudera manager管理集群,并不是读取传统上的配置文件,比如你修改/etc/hadoop/conf再重启hdfs是无效的。clouder manager区分server配置和client配置,比如,对hdfs而按,如果你作为一个client读取hdfs那么你可以使用/etc/hadoop/conf/hdfs-site.xml,但是,hdfs role instance比如namenode和datanode,都放在自己私有的配置目录,形如 /var/run/cloudera-scm-agent/process/unique-process-name。 ... 这里有非常多的内容 1.2.2 cloudera manager admin conslole 1.2.3 coludera manager api 1.2.4 扩展cloudera manager 1.3 cloudera navigate 2 overview 1.4 faq about cloudera software 1.5 getting support 2. cloudera realease notes 3. cloudera quickstart 4. cloudera install and update 5. cloudera administration 6. cloudera data management 7. cloudera operation 8. cloudera security 9. impala guide 10. cloudera search guid 11. spark guide 12. cloudera glossary
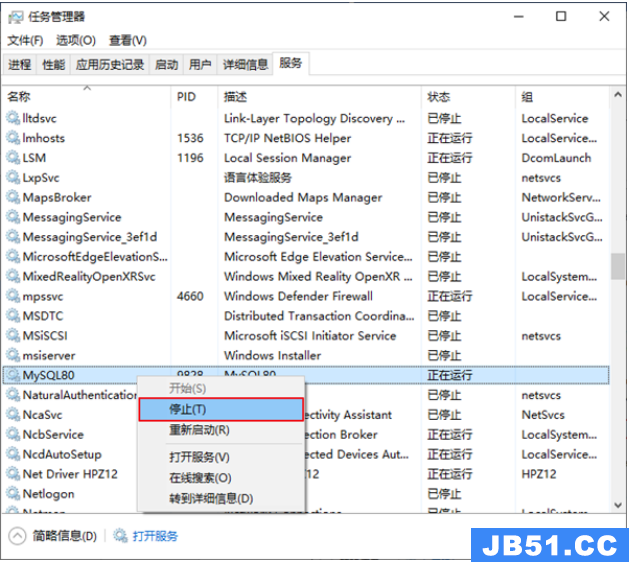 文章浏览阅读5.3k次,点赞10次,收藏39次。本章详细写了mysq...
文章浏览阅读5.3k次,点赞10次,收藏39次。本章详细写了mysq...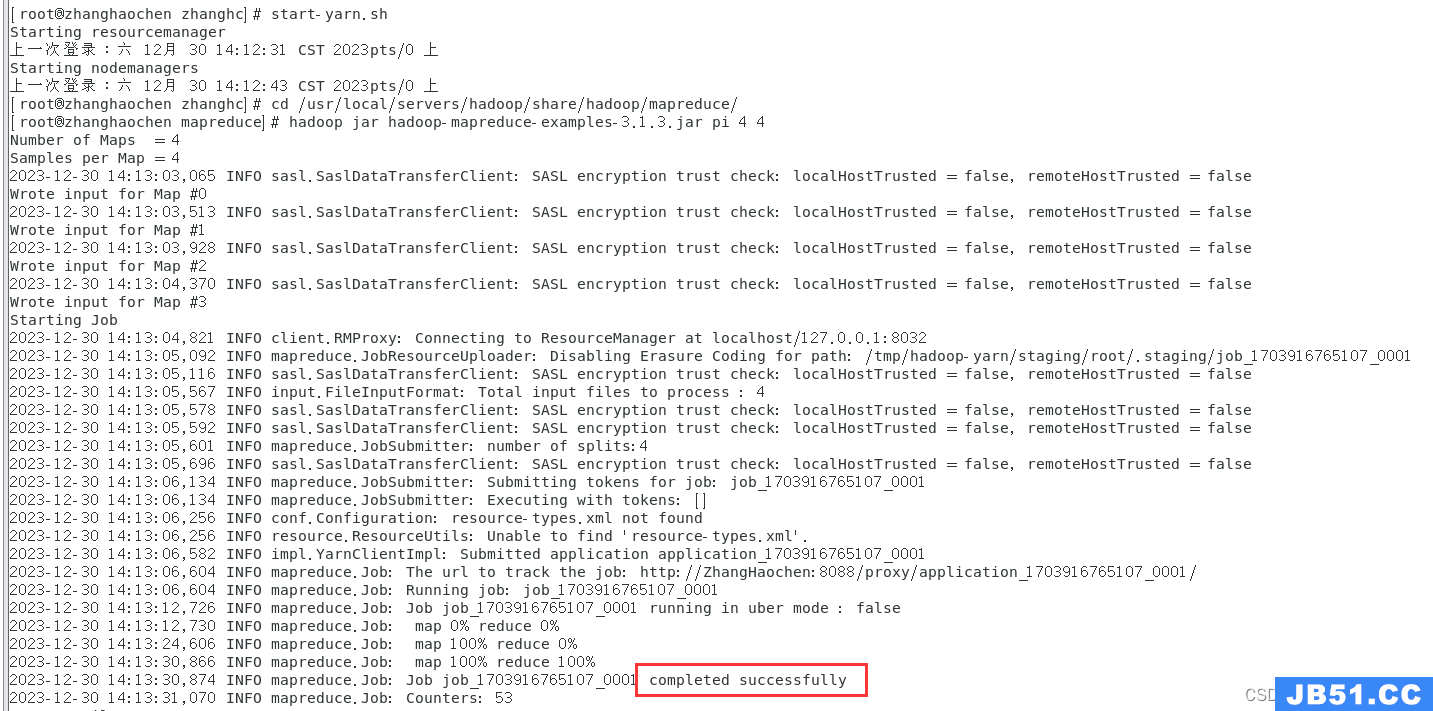 文章浏览阅读1.8k次,点赞50次,收藏31次。本篇文章讲解Spar...
文章浏览阅读1.8k次,点赞50次,收藏31次。本篇文章讲解Spar...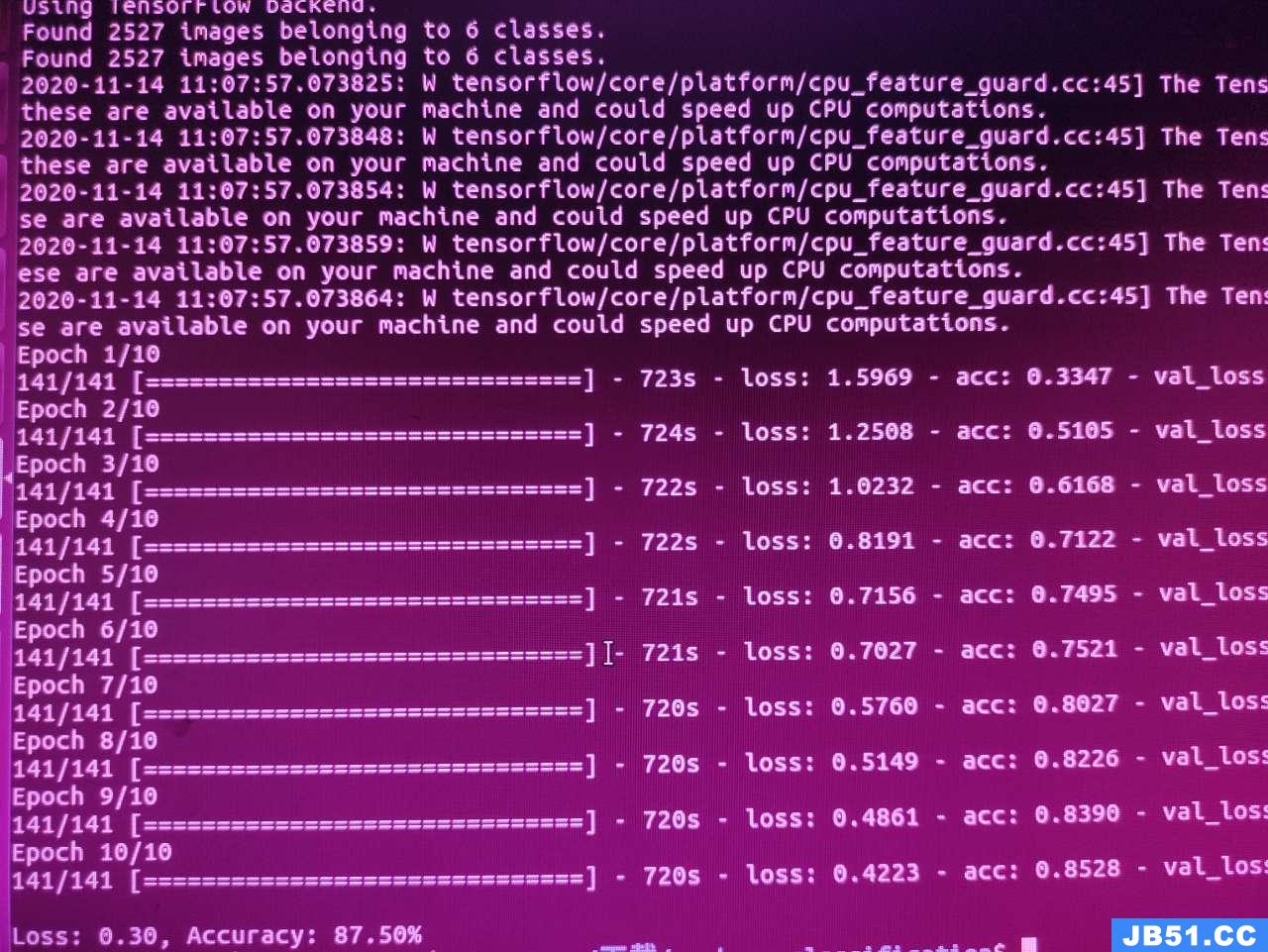 文章浏览阅读928次,点赞27次,收藏18次。
文章浏览阅读928次,点赞27次,收藏18次。 文章浏览阅读1.1k次,点赞24次,收藏24次。作用描述分布式协...
文章浏览阅读1.1k次,点赞24次,收藏24次。作用描述分布式协... 文章浏览阅读1.5k次,点赞26次,收藏29次。为贯彻执行集团数...
文章浏览阅读1.5k次,点赞26次,收藏29次。为贯彻执行集团数...