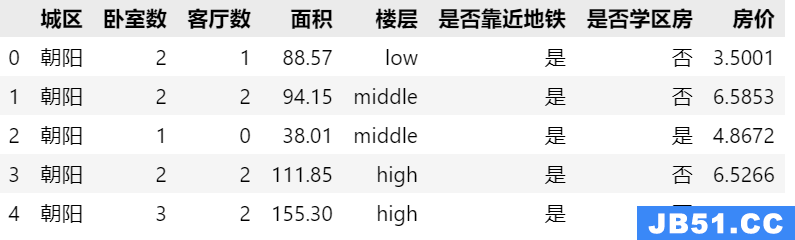
Apache Spark和
Apache Storm之间有什么区别?每个合适的用例是什么?
解决方法
Apache Spark是一个内存中分布式数据分析平台 – 主要用于加速批处理分析作业,迭代机器学习作业,交互式查询和图形处理。
Spark的主要区别之一是它使用RDDs或弹性分布式数据集。 RDD非常适合用于计算的并行运算符的流水线,并且根据定义是不变的,这允许Spark基于沿袭信息的独特形式的容错。如果您对于例如更快地执行Hadoop MapReduce作业感兴趣,Spark是一个不错的选项(虽然必须考虑内存需求)。
Apache Storm专注于流处理或者一些调用复杂事件处理。 Storm实现一种容错方法,用于在事件流入系统时执行计算或流水线化多个计算。人们可以使用Storm在非结构化数据流入系统到期望的格式时对其进行转换。
Storm和Spark专注于相当不同的用例。由于Spark的RDD本质上是不可变的,Spark Streaming实现了一种方法,用于在用户定义的时间间隔中对传入的更新进行“批处理”,并将其转换为自己的RDD。 Spark的并行运算符然后可以对这些RDD执行计算。这与Storm处理每个事件不同。
这两种技术之间的一个关键区别是,Spark执行Data-Parallel computations而Storm执行Task-Parallel computations.两种设计都要做出值得了解的权衡。我建议检查这些链接。
编辑:今天发现this