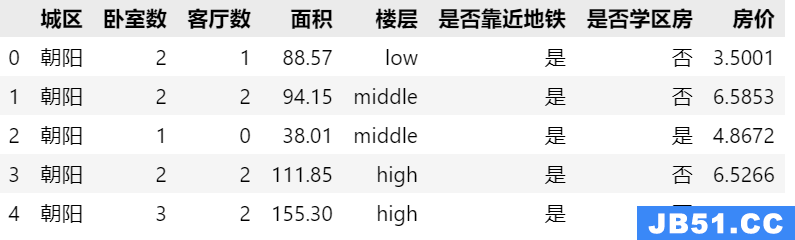
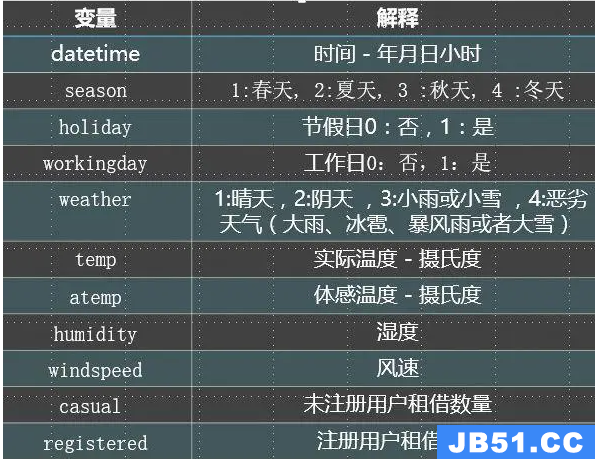
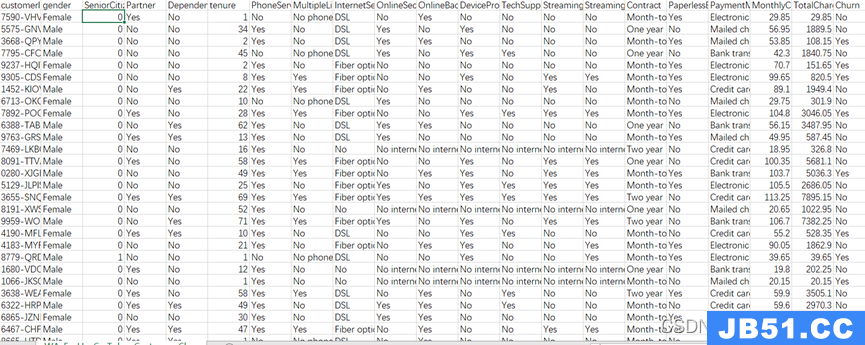
输入:短语1,短语2
输出:语义相似性值(在0和1之间),或这两个短语谈论同一事物的概率
解决方法
你可能想看看这篇文章:
Sentence similarity based on semantic nets and corpus statistics (PDF)
我已经实现了所描述的算法。我们的上下文是非常笼统的(有效地任何两个英语句子),我们发现采取的方法太慢,结果,虽然有希望,不够好(或可能是没有相当的,额外的努力)。
你不会给出很多上下文,所以我不一定推荐这个,但阅读本文可能有助于你理解如何解决这个问题。
问候,
马特。