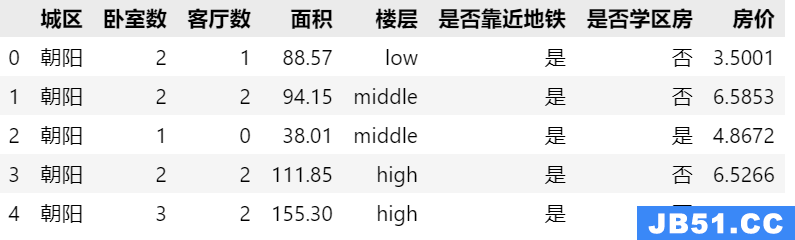
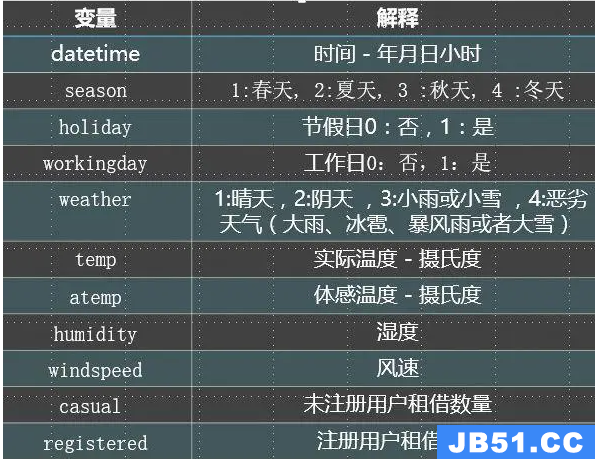
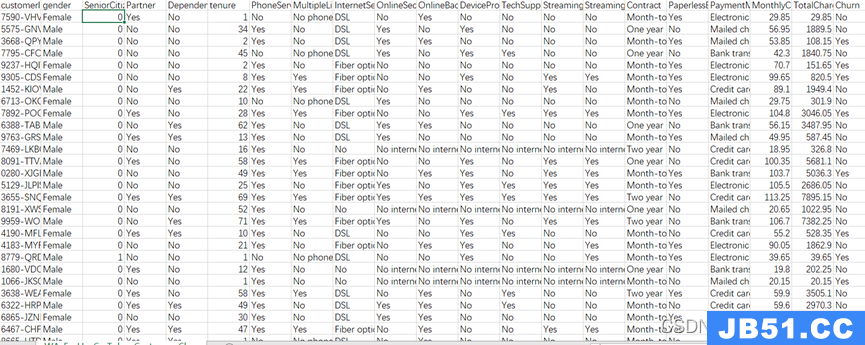
假设我的系统想要收听用户的点击事件并将其保存到存档存储中.我知道事件的来源(userId – 大约有数百个用户),以及点击的URL. (网址 – 无限变化)
class ClickEvent {
String userId;
String url;
}
如果我的系统每秒可能会收到数千个事件,我不希望通过每次点击事件调用它来将大量负载放入存储中.假设存储是类似AWS S3的存储或数据仓库,擅长存储较少数量的商店大文件,而不是每秒提交数万个请求.
我目前的方法是使用GoogleGuava的缓存库. (或只是具有缓存到期支持的任何缓存)
假设缓存的密钥是userId,缓存的值是List< url>.
>缓存未命中 – >在缓存中添加一个条目(userId,[url1])
>缓存命中 – >我将新URL附加到列表中(userId,[url1,url2 …])
>自初始写入后或在具有10000个URL之后,高速缓存条目在可配置的X min之后到期.
>在输入到期时,我将数据推送到存储中,理想情况下,将最多10000个小的单独事务减少到1个大事务.
我不确定是否有“标准”或更好的方法(甚至是一个众所周知的库)来解决这个问题,即每秒累积数千个事件并将它们全部保存在存储/文件/数据仓库中曾经,而不是将高顶负荷转移到下游服务.我觉得这是大数据系统的常见用例之一.
解决方法
我将创建一个eventModule类来获取这些事件并将它们保存在队列中.确保它是单例,以便您可以从代码中的多个位置加载它:
https://sourcemaking.com/design_patterns/singleton
https://sourcemaking.com/design_patterns/singleton
然后我会创建类类型的事件并使用工厂模式来创建它们:
https://sourcemaking.com/design_patterns/factory_method
这样,如果您需要多种事件,您的单身人士将能够处理所有事件.
最后,我会让eventModule每隔X秒将这些内容存储到本地存储.每隔Y秒(或队列中的Z事件)我会尝试将它们发送到远程存储器.如果可行,请将其从队列中删除.
这将使您在应用程序增长时具有很大的灵活性.