Kudu的读写原理
一、工作模式
Kudu的工作模式如下图,有些在上面的内容中已经介绍了,这里简单标注一下:
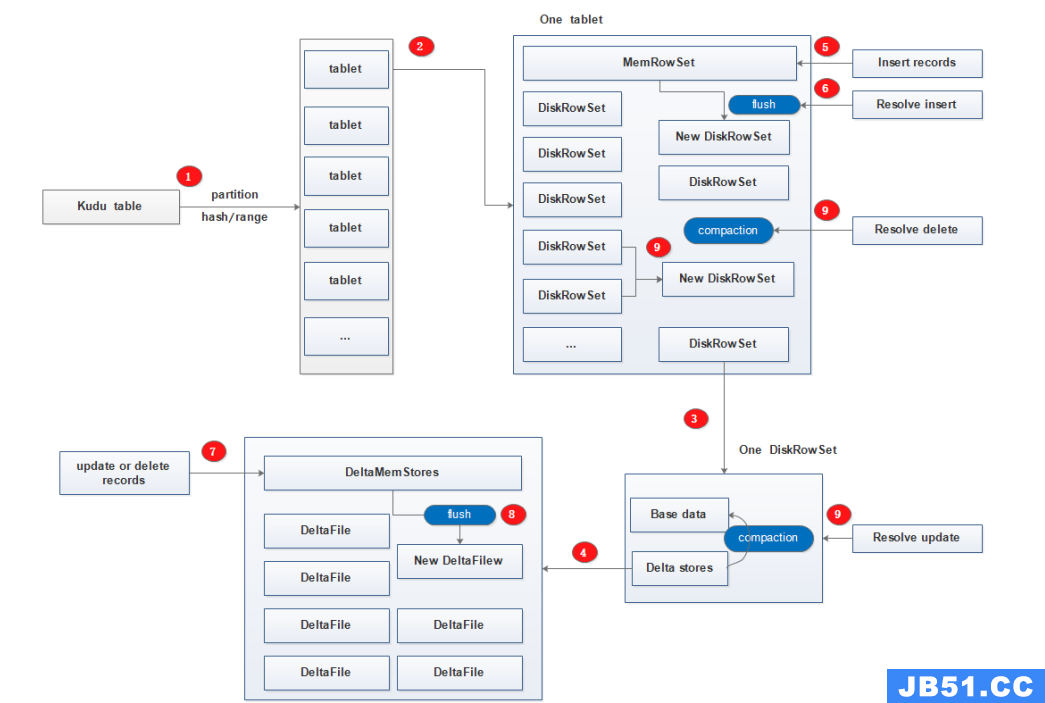
- 每个kudu table按照hash或range分区为多个tablet;
- 每个tablet中包含一个MemRowSet以及多个diskRowSet;
- 每个diskRowSet包含BaseData以及DeltaStores;
- DeltaStores由多个DeltaFile和一个DeltaMemStore组成;
- insert请求的新增数据以及对MemRowSet中数据的update操作(新增的数据还没有来得及触发compaction操作再次进行更新操作的新数据) 会先进入到MemRowSet;
- 当触发flush条件时将新增数据真正的持久化到磁盘的diskRowSet内;
- 对老数据的update和delete操作是提交到内存中的DeltaMemStore;
- 当触发flush条件时会将更新和删除操作持久化到磁盘diskRowSet中的DeltaFile内,此时老数据还在BaseData内(逻辑删除),新数据已在D