我正在做一些数据处理,我已经在Windows中构build了一个Python的程序,现在我想在我的Linux机器上运行它,所以当我回家喝啤酒时,它可能会紧缩。
一块代码(一个重要的代码)通过Numpy的genfromtxt方法从CSV文件中提取一些列值。 有问题的代码片段是:
rfd_values = np.genfromtxt(file_in,delimiter=',',skip_header=1,invalid_raise=0,usecols = cols)
所以这里的想法是,跳过标题,分隔符是一个逗号,并给我只有从列表调用cols列。 这在我的Windows笔记本电脑(相同版本的Python和Numpy,分别是2.6和1.5)上运行得很快,但是当我在Linux中运行时,它告诉我:
* TypeError:genfromtxt()得到了一个意想不到的关键字参数'skip_header'*
awk将CSV文件(加载到oracle)的特定值转换为不带引号| awk | unix
如何使用unix工具合并来自同一列的行
csv的合并打破了变音符号
Windows任务计划程序 – 将文件从URL复制到桌面
Windows环境下的csv查看器为10MM行文件
我试着把所有东西都放在一行上,并且改变了围绕分隔符关键字的引号,但那似乎不起作用。 它可能是愚蠢的,但我似乎无法把它指向它。 我浏览了一大堆论坛和Numpy文档,没有看到任何与我所看到的相近的东西。 我想知道我错过了什么。
我非常感谢任何见解。
提前致谢!
-Jeff
对文件夹中的每个文件运行命令,然后保存输出
在bash中读取一个CSV文件
linux命令根据模式将大型csv文件转换为交替行
如何使用C ++列出Windows目录中的所有CSV文件?
如何获得CSV文本文件中特定字段的最大值?
你说你实际上在Linux上使用1.3版本。 那个有一个和skiprows相同的参数skip_header 。 考虑到numpy.genfromtxt甚至没有在1.3的文档,我猜测它只是在1.3测试,最后的签名没有设置。 这就是说,你的情况有一个解决方法。 您可以使用names=True关键字参数。 在这种情况下,第一行将不会用于数据,而是用于确定列名(您可以使用该列名,而不是列表中作为usecols传递的列号)。
但还有一个问题。 invalid_raise参数也不在1.3中。
 引言 本文从Linux小白的视角, 在CentOS 7.x服务器上搭建一个...
引言 本文从Linux小白的视角, 在CentOS 7.x服务器上搭建一个... 引言: 多线程编程/异步编程非常复杂,有很多概念和工具需要...
引言: 多线程编程/异步编程非常复杂,有很多概念和工具需要...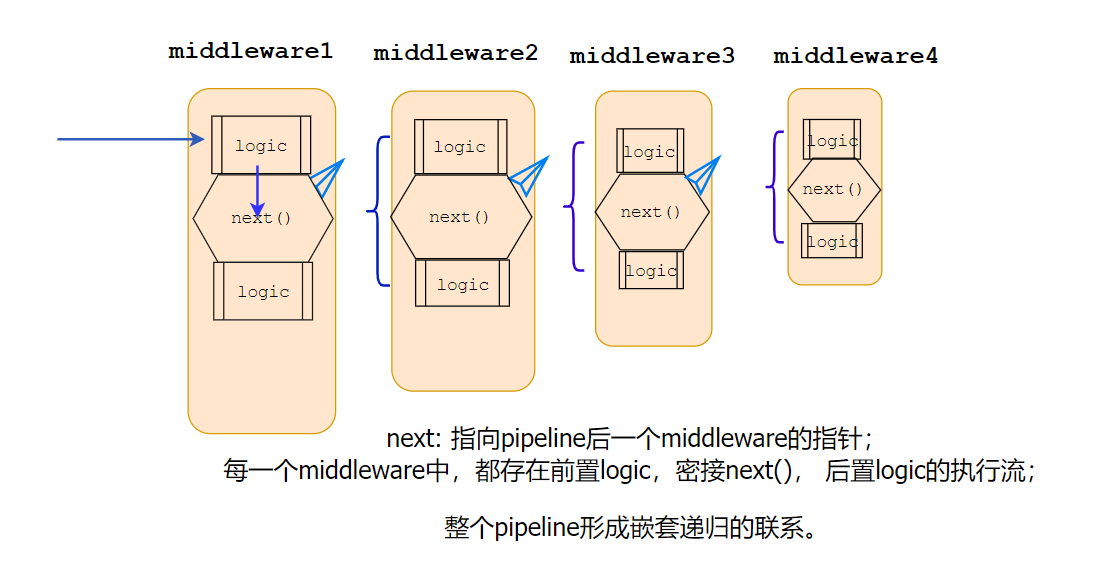 一. 宏观概念 ASP.NET Core Middleware是在应用程序处理管道...
一. 宏观概念 ASP.NET Core Middleware是在应用程序处理管道... 背景 在.Net和C#中运行异步代码相当简单,因为我们有时候需要...
背景 在.Net和C#中运行异步代码相当简单,因为我们有时候需要...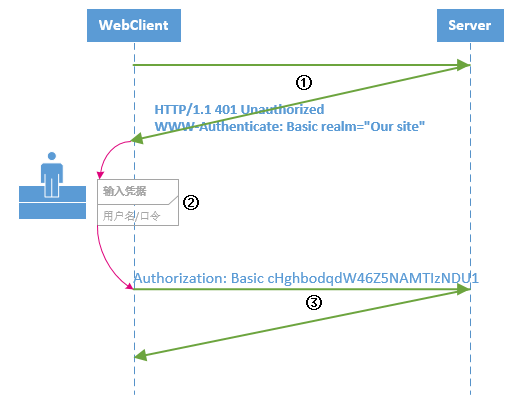 HTTP基本认证 在HTTP中,HTTP基本认证(Basic Authenticatio...
HTTP基本认证 在HTTP中,HTTP基本认证(Basic Authenticatio... 1.Linq 执行多列排序 OrderBy的意义是按照指定顺序排序,连续...
1.Linq 执行多列排序 OrderBy的意义是按照指定顺序排序,连续...