《Apache Spark 1.6发布》要点:
本文介绍了Apache Spark 1.6发布,希望对您有用。如果有疑问,可以联系我们。
编程之家PHP培训学院每天发布《Apache Spark 1.6发布》等实战技能,PHP、MYSQL、LINUX、APP、JS,CSS全面培养人才。
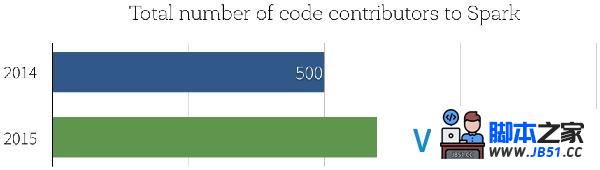
本日我们非常高兴能够发布Apache Spark 1.6,通过该版本,Spark在社区开发中达到一个重要的里程碑:Spark源码贡献者的数据已经超过1000人,而在2014年年末时人数只有500.
那么,Spark 1.6有什么新特性呢?Spark 1.6有逾千个补丁.在本博文中,我们将重点突出三个主要的开发主题:性能提升、新的DataSet API和数据科学函数的扩展.
性能提升
根据我们2015年Spark调查申报,91%的用户认为性能是Spark最重要的方面,因此,性能优化是我们进行Spark开发的一个重点.
Parquet性能:Parquet已经成为Spark中最常用的数据格式之一,同时Parquet扫描性能对许多大型应用程序的影响巨大.在以前,Spark的Parquet读取器依赖于parquet-mr去读和解码Parquet文件.当我们在编写Spark应用程序时,必要花很多的时间在“记录装配(record assembly)”上,以使进程能够将Parquet列重建为数据记录.在Spark 1.6中,我们引入了新的Parquet读取器,它绕过parquert-mr的记录装配并使用更优化的代码路径以获取扁平模式(flat schemas).在我们的基准测试当中,通过5列测试发现,该新的读取器扫描吞吐率可以从290万行/秒增加到450万行/秒,性能提升接近50%.
自动内存管理:Spark 1.6中另一方面的性能提升来源于更良好的内存管理,在Spark 1.6之前,Spark静态地将可用内存分为两个区域:执行内存和缓存内存.执行内存为用于排序、hashing和shuffling的区域,而缓存内存为用于缓存热点数据的区域.Spark 1.6引入一新的内存管理器,它可以自动调整不同内存区域的大小,在运行时根据执行程序的必要自动地增加或缩减相应内存区域的大小.对许多应用程序来说,它意味着在无需用户手动调整的情况下,在进行join和aggregration等操作时其可用内存将大量增加.
前述的两个性能提升对用户来说是透明的,使用时无需对代码进行修改,而下面的改进是一个新API能够保证更好性能的例子.
流式状态管理10倍性能提升:在流式应用程序当中,状态管理是一项重要的功能,常常用于维护aggregation或session信息.通过和许多用户的共同努力,我们对Spark Streaming中的状态管理API进行了重新设计,引入了一个新的mapWithState API,它可以根据更新的数量而非整个记录数进行线性扩展,也便是说通过跟踪“deltas”而非总是进行所有数据的全量扫描的方式更加高效.在许多工作负载中,这种实现方式可以获得一个数量级性能提升.我们创建了一个notebook以说明如何使用该新特性,不久后我们也将另外撰写相应的博文对这部分内容进行说明.
Dataset API
在本年较早的时候我们引入了DataFrames,它提供高级函数以使Spark能够更好地理解数据结构并执行计算,DataFrame中额外的信息可以使Catalyst optimizer和Tungsten执行引擎(Tungsten execution engine)自动加速实际应用场景中的大数据分析.
自从我们发布DataFrames,我们得到了大量反馈,其中缺乏编译时类型平安支持是诸多重要反馈中的一个,为解决这该问题,我们正在引入DataFrame API的类型扩展即Datasets.
Dataset API通过扩展DataFrame API以支持静态类型和用户定义函数以便能够直接运行于现有的Scala和Java类型基础上.通过我们与经典的RDD API间的比拟,Dataset具有更好的内存管理和长任务运行性能.
请参考Spark Datasets入门这篇博文.
新数据科学函数
机器学习流水线持久化:许多机器学习应用利用Spark ML流水线特性构建学习流水线,在过去,如果程序想将流水线持久化到外部存储,需要用户自己实现对应的持久化代码,而在Spark 1.6当中,流水线API提供了相应的函数用于保留和重新加载前一状态的流水线,然后将前面构建的模型应用到后面新的数据上.例如,用户通过夜间作业训练了一个流水线,然后在生产作业中将其应用于生产数据.
新的算法和能力:本版本同时也增加了机器学习算法的范围,包含:
- 单变量和双变量统计
- 存活分析
- 最小二乘法尺度方程
- 平分K均值聚类
- 联机假设检验
- ML流水线中的隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)
- 广义线性模型(General Liner Model,GLM)类R统计
- R公式中的特征交互
- GLM实例权重
- DataFrames中的单变量和双变量统计
- LIBSVM数据源
- 非尺度JSON数据
本博文只给出了本发布版本中的主要特性,我们也编译了.
在接下来的几周内,我们将陆续推出对这些新特性进行更详细说明的博文,请继承关注Databricks博客以便了解更多关于Spark 1.6的内容.如果你想试用这些新特性,Databricks可以让你在保存老版本Spark的同时使用Spark 1.6.注册以获取免费试用帐号.
若没有1000个源码贡献者,Spark现在不可能如此成功,我们也趁此机会对所有为Spark贡献过力量的人表现感谢.
原文地址:Announcing Spark 1.6(译者/牛亚真 审校/朱正贵 责编/仲浩)
译者介绍:牛亚真,中科院计算机信息处置专业硕士研究生,关注大数据技术和数据挖掘方向.