一、多级分类问题
在实际开发的过程中,会经常遇到多级分类的问题。譬如,导航栏、菜单、商品种类、多级联动、字典表等等的多级分类问题。这时可以新增一个 pid 字段进行数据关联,它本质上其实就是一棵树。树就可以很好的解决多级分类的子分类查询。
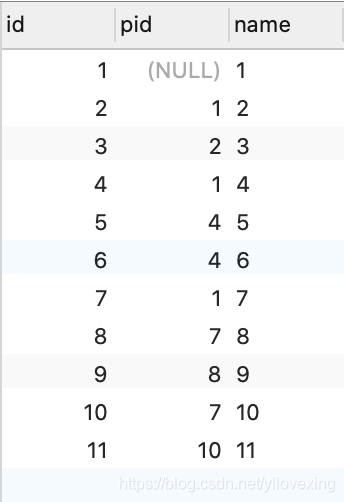
但是这种方式有一个致命的问题:查询效率过低!!!
当我们在程序里查询某个子节点时,要先从根节点进行递归查询,时间复杂度是 O(n)。
那么有没有一种方式,改进树的查询效率呢?答案是肯定的!很多树都在标准的树上进行改进过,比如二叉树、红黑树、堆等等。但这都不是重点,今天要分享的是 预排序遍历树算法(MPTT)。
MPTT 正是为了解决多层级关系数据的查询效率问题,它的时间复杂度竟然能高效到一个常量,即 O(1)。是不是很不可思议,接下来就让我们一起学习预排序遍历树算法,看下它到底是如何实现的。
二、预排序遍历树
预排序遍历树算法全称是:Modified Preorder Tree Traversal 简称 MPTT。
1. ORM 映射
class Tree(Base,BaseNestedSets):
__tablename__ = 'tree'
id = Column(Integer,primary_key=True,autoincrement=True)
name = Column(String(8),nullable=True,default=None)
def __repr__(self):
return f'<Tree(id={self.id},name={self.name})>'
2. MPTT 分析
在上述代码中,只定义了两个字段: id、name。但是数据库里面却额外多出了 5个字段,分别是: lft、rgt、level、tree_id、parent_id。
这些多出来的字段就是为了定义树的结构和层级。下面我们就来分析一下,每个字段的作用是什么。
-
tree_id:树的id,用来区分数据库中众多树的某一颗树。 -
level:一颗标准的树会有高度、深度、层级,根节点的层级是1,子节点的层级是父节点层级加1。 -
parent_id:父id,节点的父级id,根节点没有父节点,所以值为NULL。 -
lft:节点左值。 -
rgt:节点右值。
节点的左值和右值是 MPTT 的核心,也是这个算法实现特别巧妙的地方,将树遍历的时间复杂度降为 O(1)。接下来就重点分析一下左值与右值是如何进行树遍历的。
一颗标准的树结构:

数据库数据对应关系:

数据层次结构:
- 【1】
- - 【2】
- - - 【3】
- - 【4】
- - - 【5】
- - - 【6】
- - 【7】
- - - 【8】
- - - - 【9】
- - - 【10】
- - - - 【11】
遍历整棵树
遍历整棵树只需要查找 tree_id 等于 1 的条件即可
找到某节点下所有的子孙节点
查找节点 4 的所有子孙节点,以 4 作为参考点。左值大于 6 且右值小于 11 的所有子孙节点,就是节点 4 的所有子孙节点。
找到某节点下所有的子节点
查找节点 1 的所有子节点,以 1 作为参考点。tree_id 等于 1 且 level 等于 2。
查找某节点的路径
查找节点 9 的所有上级路径,以 9 作为参考点。左值小于 14 且右值大于 15 的所有节点,就是节点 ``9的路径。结果是:1 -> 7 -> 8 -> 9`。
3. MPTT 平衡算法
MPTT 在遍历的时候很快,但是其他的操作就会变得很慢,所以使用 MPTT 要尽量避免查询之外的其他操作。

那为什么除了查询操作其他的操作会很慢呢?
这是因为节点在插入、更新(移动)、删除会破坏树的平衡。所以在做这些操作的时候需要对数进行调整,达到新的平衡。
新增
以新增节点操作为例,算法可分解为以下几个步骤:
-
如果要在不存在的树中新增节点,即要创建一颗新树。那么它是没有
parent_id的,所以parent_id值为NULL,level是1,tree_id是根据已有树的最大tree_id加1。 -
如果要在已存在的树中新增节点。那么它的
parent_id是父节点的id,level是父节点的level加1,tree_id和父节点保持一致。 -
修复被破坏平衡的其他节点的左值。大于
parent_id右值的所有节点的左值加2。 -
修复被破坏平衡的其他节点的右值。大于等于
parent_id右值的所有节点的右值加2。
删除
和增加类似,只不过删除一个节点以后对左值和右值进行相反的操作,即减 2。
更新(移动)
更新(移动)其实就是删除一个老节点,再新增一个新节点,具体算法参考上面的例子。
三、标准树和预排序遍历树的优劣对比
-
标准树:适用于增删 操作较多的场景,每次删改只需要修改一条数据。在查询方面,随着分类层级的增加邻接表的递归查询效率逐渐降低。 -
预排序遍历树:适用于查询操作较多的场景,查询的效率不受分类层级的增加的影响,但是随着数据的增多,每增删数据,都要同时操作多条受影响数据,执行效率逐渐下降。
没有完美的算法,在实际开发过程中具体要选择哪一种存储结构和算法,需要根据具体的应用场景来做选择。