<div id="article_content" class="article_content clearfix csdn-tracking-statistics" data-pid="blog" data-mod="popu_307" data-dsm="post">
<div id="content_views" class="htmledit_views">
上一篇:
68、Java中如何实现序列化,有什么意义?
答:序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化。可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间。序列化是为了解决对象流读写操作时可能引发的问题(如果不进行序列化可能会存在数据乱序的问题)。
要实现序列化,需要让一个类实现Serializable接口,该接口是一个标识性接口,标注该类对象是可被序列化的,然后使用一个输出流来构造一个对象输出流并通过writeObject(Object)方法就可以将实现对象写出(即保存其状态);如果需要反序列化则可以用一个输入流建立对象输入流,然后通过readObject方法从流中读取对象。序列化除了能够实现对象的持久化之外,还能够用于对象的深度克隆(可以参考第29题)。
69、Java中有几种类型的流?
答:字节流和字符流。字节流继承于InputStream、OutputStream,字符流继承于Reader、Writer。在 java.io 包中还有许多其他的流,主要是为了提高性能和使用方便。关于Java的I/O需要注意的有两点:一是两种对称性(输入和输出的对称性,字节和字符的对称性);二是两种设计模式(适配器模式和装潢模式)。另外Java中的流不同于C#的是它只有一个维度一个方向。
面试题 - 编程实现文件拷贝。(这个题目在笔试的时候经常出现,下面的代码给出了两种实现方案)
注意:上面用到Java 7的TWR,使用TWR后可以不用在finally中释放外部资源 ,从而让代码更加优雅。
70、写一个方法,输入一个文件名和一个字符串,统计这个字符串在这个文件中出现的次数。
答:代码如下:
71、如何用Java代码列出一个目录下所有的文件?
答:
如果只要求列出当前文件夹下的文件,代码如下所示:
如果需要对文件夹继续展开,代码如下所示:
在Java 7中可以使用NIO.2的API来做同样的事情,代码如下所示:
72、用Java的套接字编程实现一个多线程的回显(echo)服务器。
答:
注意:上面的代码使用了Java 7的TWR语法,由于很多外部资源类都间接的实现了AutoCloseable接口(单方法回调接口),因此可以利用TWR语法在try结束的时候通过回调的方式自动调用外部资源类的close()方法,避免书写冗长的finally代码块。此外,上面的代码用一个静态内部类实现线程的功能,使用多线程可以避免一个用户I/O操作所产生的中断影响其他用户对服务器的访问,简单的说就是一个用户的输入操作不会造成其他用户的阻塞。当然,上面的代码使用线程池可以获得更好的性能,因为频繁的创建和销毁线程所造成的开销也是不可忽视的。
下面是一段回显客户端测试代码:
如果希望用NIO的多路复用套接字实现服务器,代码如下所示。NIO的操作虽然带来了更好的性能,但是有些操作是比较底层的,对于初学者来说还是有些难于理解。
73、XML文档定义有几种形式?它们之间有何本质区别?解析XML文档有哪几种方式?
答:XML文档定义分为DTD和Schema两种形式,二者都是对XML语法的约束,其本质区别在于Schema本身也是一个XML文件,可以被XML解析器解析,而且可以为XML承载的数据定义类型,约束能力较之DTD更强大。对XML的解析主要有DOM(文档对象模型,Document Object Model)、SAX(Simple API for XML)和StAX(Java 6中引入的新的解析XML的方式,Streaming API for XML),其中DOM处理大型文件时其性能下降的非常厉害,这个问题是由DOM树结构占用的内存较多造成的,而且DOM解析方式必须在解析文件之前把整个文档装入内存,适合对XML的随机访问(典型的用空间换取时间的策略);SAX是事件驱动型的XML解析方式,它顺序读取XML文件,不需要一次全部装载整个文件。当遇到像文件开头,文档结束,或者标签开头与标签结束时,它会触发一个事件,用户通过事件回调代码来处理XML文件,适合对XML的顺序访问;,StAX把重点放在流上,实际上StAX与其他解析方式的本质区别就在于应用程序能够把XML作为一个事件流来处理。将XML作为一组事件来处理的想法并不新颖(SAX就是这样做的),但不同之处在于StAX允许应用程序代码把这些事件逐个拉出来,而不用提供在解析器方便时从解析器中接收事件的处理程序。
74、你在项目中哪些地方用到了XML?
答:XML的主要作用有两个方面:数据交换和信息配置。在做数据交换时,XML将数据用标签组装成起来,然后压缩打包加密后通过网络传送给接收者,接收解密与解压缩后再从XML文件中还原相关信息进行处理,XML曾经是异构系统间交换数据的事实标准,但此项功能几乎已经被JSON(JavaScript Object Notation)取而代之。当然,目前很多软件仍然使用XML来存储配置信息,我们在很多项目中通常也会将作为配置信息的硬代码写在XML文件中,Java的很多框架也是这么做的,而且这些框架都选择了dom4j作为处理XML的工具,因为Sun公司的官方API实在不怎么好用。
补充:现在有很多时髦的软件(如Sublime)已经开始将配置文件书写成JSON格式,我们已经强烈的感受到XML的另一项功能也将逐渐被业界抛弃。
75、阐述JDBC操作数据库的步骤。
答:下面的代码以连接本机的Oracle数据库为例,演示JDBC操作数据库的步骤。
加载驱动。









 在 Java 语言中,提高程序的执行效率有两种实现方法,一个是...
在 Java 语言中,提高程序的执行效率有两种实现方法,一个是...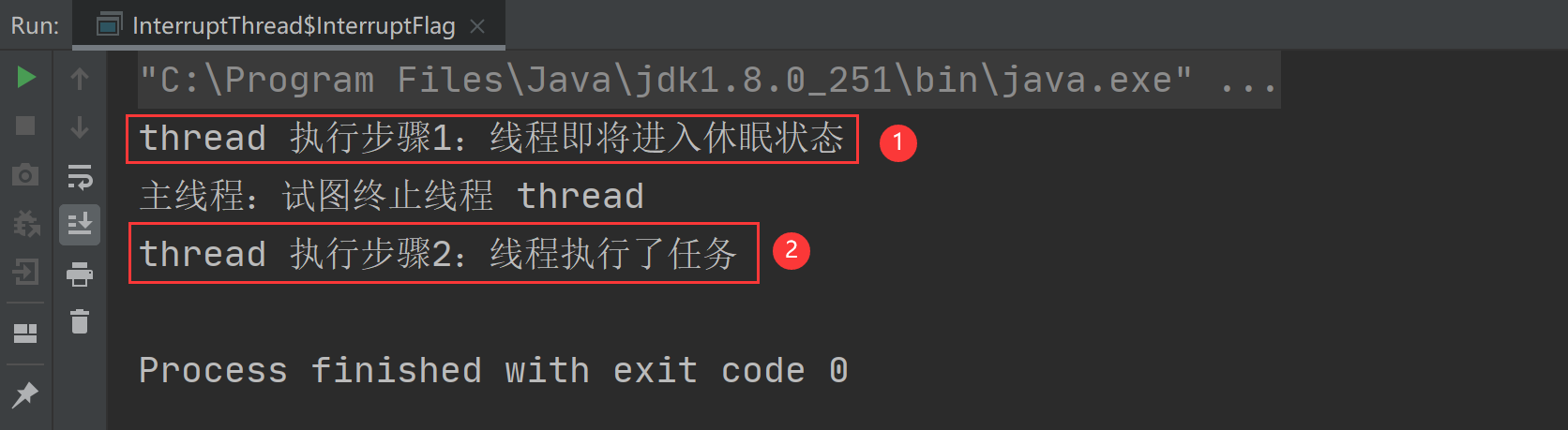 在 Java 中停止线程的实现方法有以下 3 种: 自定义中断标识...
在 Java 中停止线程的实现方法有以下 3 种: 自定义中断标识...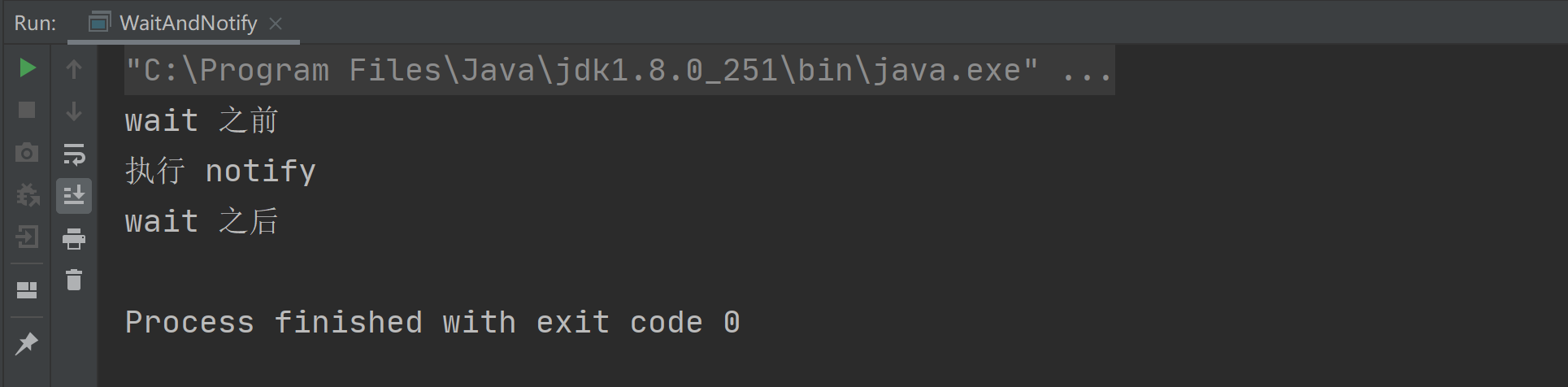 在多线程编程中,wait 方法是让当前线程进入休眠状态,直到另...
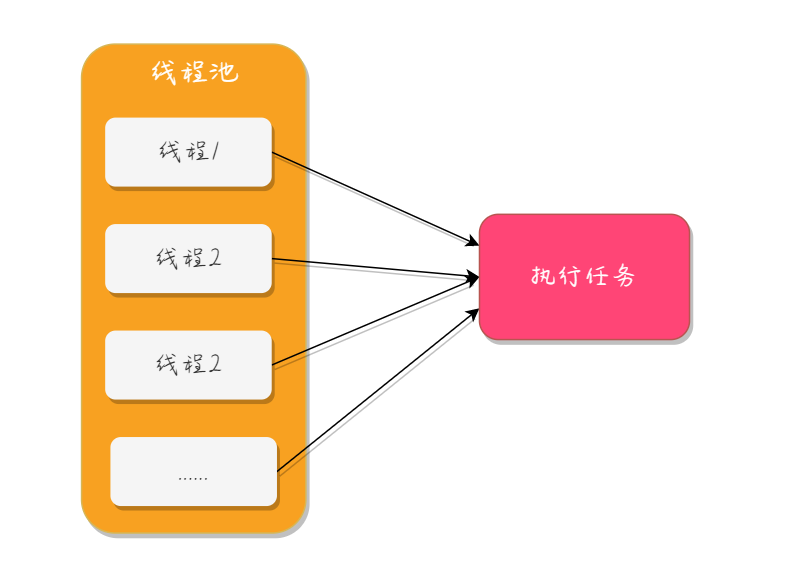
在多线程编程中,wait 方法是让当前线程进入休眠状态,直到另...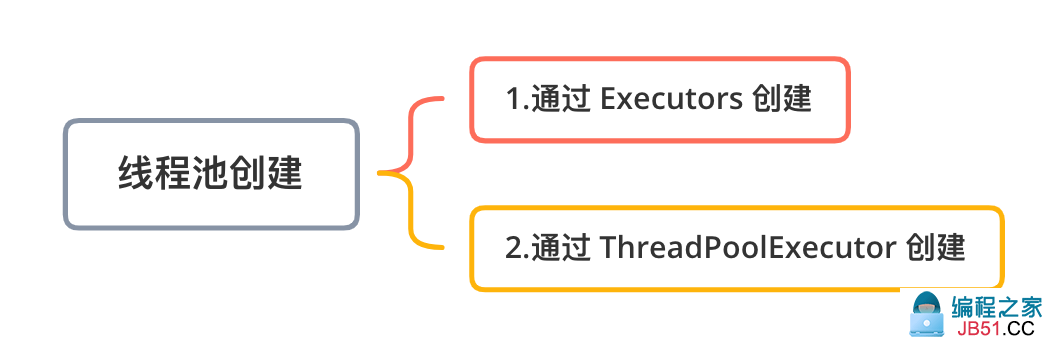 在 Java 语言中,并发编程都是通过创建线程池来实现的,而线...
在 Java 语言中,并发编程都是通过创建线程池来实现的,而线... sleep 方法和 wait 方法都是用来将线程进入休眠状态的,并且...
sleep 方法和 wait 方法都是用来将线程进入休眠状态的,并且...